Fundamentals of Data Engineering
Table of contents
- 1: Data Engineering Described
- 2: The Data Engineering Lifecycle
- 3: Designing Good Data Architecture
- 4: Choosing Technologies Across the Data Engineering Lifecycle
- 5: Data Generation in Source Systems
- 6: Storage
1: Data Engineering Described
what is data engineering?
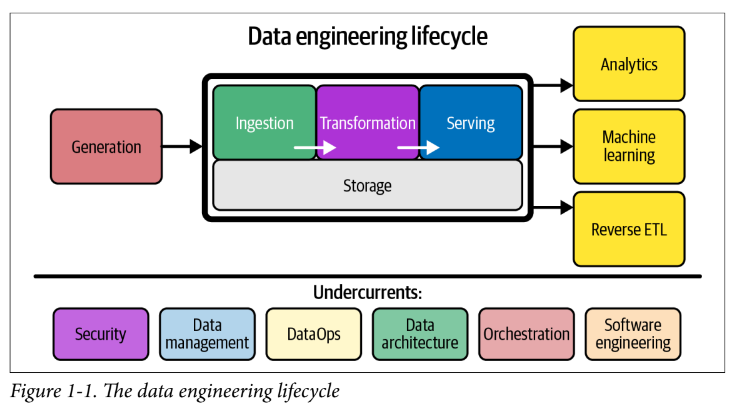
Data engineering is the development, implementation, and maintenance of systems and processes that take in raw data and produce high-quality, consistent information,that supports downstream use cases, such as analysis and machine learning. Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration, and software engineering. A data engineer manages the data engineering lifecycle, beginning with getting data from source systems and ending with serving data for use cases, such as analysis or machine learning.
Evolution of Data Engineer
- has it’s roots in the business data warehouse (coined by Bill Inmon in 1989 but predates this to the 70s)
- IBM creates SQL in the 90s
- massively parallel processing (MPP) databases expanded the utility of data crunching
- in early 2000s, powerhouse tech companies emerge (Google, Yahoo, Amazon, etc)
- these companies begin working on big data and creating open source utilities (like Yahoo and Hadoop or Google and MapReduce) to handle
- big data engineers evolved to use these big data tools
- eventually, big data began to lose steam because of simplification (big data tools are tricky to work with and require specialization)
- with advent of cloud, that brought about decentralized, modularized, managed, and highly abstracted tools and generalized big data engineer to just data engineer

- data engineering straddles the divide between getting data and getting value from data
Data Engineering Skills
- skill set of a data engineer encompasses the “undercurrents” of data engineering: security, data management, DataOps, data architecture, and software engineering
- the data engineer juggles a lot of complex moving parts and must constantly optimize along the axes of cost, agility, scalability, simplicity, reuse, and interoperability
- data engineer typically doesn’t build ML models, create reports or dashboards, perform data analysis, build key performance indicators (KPIs), or develop software applications
- data engineer must understand both data and technology, know best practice around data management, be aware of various options for tools, their interplay and tradeoff
- requires good understanding of software engineering, DataOps, and data architecture
- must understand requirements of data consumers
- languages: SQL, python, JVM (Java, Scala, Groovy), bash/powershell
Data Maturity
- Data maturity is the progression toward higher data utilization, capabilities, and integration across the organization
- starting with data
- fuzzy, loosely defined (or no) goals with data
- adoption and utilization low
- data team is small
- data engineer’s goal is to move fast, get traction, and add value
- scaling with data
- moved away from ad-hoc data requests to formal data practices
- challenge is creating scalable data architecture and planning for a future where company is data-driven
- data engineer moves from generalist to specialist
- leading with data
- company is data-driven
- automated pipelines allow people in company to self-serve analytics and ML
- introducing new data sources is seamless
Business Responsibilities
- Know how to communicate with nontechnical and technical people
- Understand how to scope and gather business and product requirements
- Understand the cultural foundations of Agile, DevOps, and DataOps
- Control costs
- Learn continuously
type A data engineers
- A for abstraction
- avoids heavy lifting
- keeps data architecture abstract and straightforward
- use off-the-shelf products
type B data engineers
- B for build
- build data tools and systems that scale and leverage company’s core competency and competitive advantage
- more often found at more data mature orgs
Stakeholders
upstream stakeholders
- data architects
- software engineers
- DevOps engineers and site-reliability engineers
downstream stakeholders
- data scientists
- data analysts
- machine learning engineers and AI researchers
2: The Data Engineering Lifecycle
- comprises stages that turn raw data ingredients into a useful end product, ready for consumption by analysts, data scientists, ML engineers, and other
- -the full data lifecycle encompasses data across its entire lifespan, the data engineering lifecycle focuses on the stages a data engineer controls
Generation
- generated from a source system - origin of data
- data engineer needs working understanding of way source systems work, generate data, frequency, velocity, and variety of data
- also need open line of communication with source system owners
- understand limitations of source system
- challenging nuance - schema (defines hierarchical organization of data)
- schemaless (on read) - enforced in applicaiton
- fixed schema (on write) - enforced in database
Storage
- data architecture leverages several storage solutions, and most don’t function purely as storage (mixing in transformation or query semantics/serving)
-
temperature of data - how frequently it is accessed
- hot - most frequent, many times a day
- lukewarm - every so often
- cold - seldom, appropriate to store in archival system
Ingestion
- source systems and ingestion represent most significant bottleneck of data engineering lifecycle
- understand use cases for data that is being ingested
- destination of data?
- what frequency, volume, format?
- batch vs streaming – batch is bounded input, streaming is continuous, microbatch is a hybrid with really small batches
- streaming is much more complicated and should be adopted only after identifying business use case that justifies the trade-offs from batch
- push data ingestion - a source system writes data out to a target, whether a database, object store, or filesystem
- pull data ingestion - data is retrieved from the source system
Transformation
- data needs to be changed from original form into something useful for downstream use cases
- basic transformations map data into correct types (changing ingested string data into numeric and date types, for example), putting records into standard formats, and removing bad ones. Later stages of transformation may transform the data schema and apply normalization. Downstream, apply large-scale aggregation for reporting or featurize data for ML processes
- without proper transform, data will sit inert
- data featurization for ML intends to extract and enhance data features useful for training ML models
Serving
- get value from data
- Data has value when it’s used for practical purposes. Data that is not consumed or queried is simply inert
Analytics
Business Intelligence
- BI marshals collected data to describe a business’s past and current state
- logic-on-read approach - data is stored in a clean but fairly raw form, with minimal postprocessing business logic
- as company grows in data maturity, move from ad-hoc to self-service analytics
Operational Analytics
- focuses on fine-grained details of operations
Embedded Analytics
- different from operational as they are customer-facing
- likely increased request rate for reports, access control is significantly more complicated and important
Machine Learning
- responsibilities of data engineers overlap significantly in analytics and ML, and the boundaries between data engineering, ML engineering, and analytics engineering can be fuzzy
- be careful not to prematurely dive into ML without appropriate data engineering foundations
Reverse ETL
- takes processed data from the output side of the data engineering lifecycle and feeds it back into source systems
- increasingly important as business rely on SaaS and external platforms, might want to push specific metrics to a CRM system, (e.g., Google Ads)
Data Engineering Undercurrents
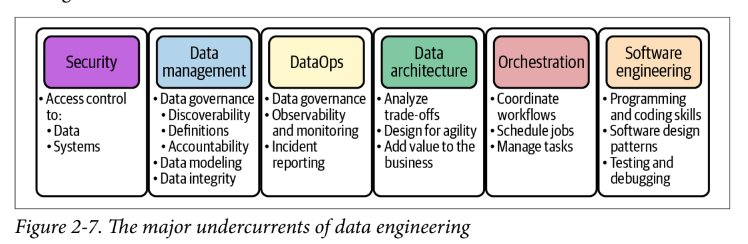
Security
- principle of least privilege - giving a user or system access to only the essential data and resources to perform an intended function
- people and org structure are always biggest security vulnerabilities
- create a culture of security that permeates the org
- also about timing – give access only for duration necessary to perform work
- data engineers must be competent security administrators, as security falls in their domain - understand security best practices for the cloud and on prem
- user and identity access management (IAM) roles, policies, groups, network security, password policies, and encryption, etc.
Data Management
Data management is the development, execution, and supervision of plans, policies, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their lifecycle.
- Data Management Body of Knoweldge (DMBOK)
Data Governance
- engages people, processes, and technologies to maximize data value across an organization while protecting data with appropriate security controls
Discoverability
- end users have quick and reliable access to data they need to do their jobs
- end users should know where the data comes from, how it relates to other data, and what data means
Metadata
- data about data
- either autogenerated or human generated – metadata collection is often manual and error prone
- technology can assist with collection and remove some errors (data catalogs, data-lineage tracking systems, metadata management tools)
types of metadata
| type | description | examples |
|---|---|---|
| business metadata | way data is used in business | business and data definitions, data rules and logic, how and where data is used, and data owners |
| technical metadata | describes the data created and used by systems across the engineering lifecycle | data model, schema, data lineage, field mappings, pipeline workflows |
| pipeline metadata | provides details of workflow schedule | schedule, system and data dependencies, configs, connection details |
| data-lineage metadata | tracks origin and changes to data, and dependencies over time | audit of data trails |
| schema metadata | describes the structure of data stored in a system such as a database, a data warehouse, a data lake, or a filesystem | schemas |
| operational metadata | describes the operational results of various systems | statistics about processes, job IDs, application runtime logs, data used in a process, and error logs |
| reference metadata | data used to classify other data | lookup data |
Data Accountability
- assigning an individual to govern a portion of data – managing data is tough if no one is accountable for the data in question
Data Quality
- optimization of data toward the desired state – what you get compared to what you expect
- should conform to expectations in business metadata
- accuracy - Is the collected data factually correct? Are there duplicate values? Are the numeric values accurate?
- completeness - Are the records complete? Do all required fields contain valid values?
- timeliness - Are records available in a timely fashion?
Data Modelling and Design
- process of converting data into a usable form
- want to avoid the write once, read never (WORN) access pattern or data swamp
Data Lineage
- recording the audit trail of data through its lifecycle, tracking both systems that process data and upstream data that it depends on
- data observability driven developement (dodd)
Data Integration and Interoperability
- process of integrating data across tools and processes
Data Lifecycle Management
- how long you retain data
- considerations:
- cost of retaining indefinitely
- privacy with things like GDPR and CCPA
Ethics and Privacy
- data engineers need to mask personally identifiable information (PII) and other sensitive info
- bias can be identified and tracked
DataOps
- maps the best practices of Agile methodology, DevOps, and statistical process control (SPC) to data
- increases release and quality of data products
- set of cultural habits
DataOps is a collection of technical practices, workflows, cultural norms, and architectural patterns that enable:
- Rapid innovation and experimentation delivering new insights to customers with increasing velocity
- Extremely high data quality and very low error rates
- Collaboration across complex arrays of people, technology, and environments
- Clear measurement, monitoring, and transparency of results
Automation
- enables reliability and consistency and allows faster deployments
- change management (environment, code, and data version control), continuous integration/continuous deployment (CI/CD), and configuration as code
- DataOps Manifesto
Observability and Monitoring
- critical to get ahead of any problems you might experience
Incident Response
- using the automation and observability capabilities mentioned previously to rapidly identify root causes of an incident and resolve it as reliably and quickly as possible
- data engineers should proactively find issues before business reports them
Data Architecture
- A data architecture reflects the current and future state of data systems that support an organization’s long-term data needs and strategy
Orchestration
- the process of coordinating many jobs to run as quickly and efficiently as possible on a scheduled cadence
- new tools like Airflow, Dagster, Prefect allow for infra as code
Software Engineering
- central skill for data engineers
- core data processing code
- development of open source frameworks
- streaming complications
- infra as code (IaC)
- pipelines as code
- general-purpose problem solving
3: Designing Good Data Architecture
Enterprise Architecture
- data architecture is part of enterprise architecture
- technical solutions exist to support business goals
- architects
- identify problems in current state (poor data quality, scalability limits, money-losing lines of business),
- define desired future states (agile data-quality improvement, scalable cloud data solutions, improved business processes), and
- realize initiatives through execution of small, concrete steps
The Open Group Architecture Framework (TOGAF) definition
The term “enterprise” in the context of “enterprise architecture” can denote an entire enterprise—encompassing all of its information and technology services, processes, and infrastructure—or a specific domain within the enterprise. In both cases, the architecture crosses multiple systems, and multiple functional groups within the enterprise.
Gartner’s definition
Enterprise architecture (EA) is a discipline for proactively and holistically leading enterprise responses to disruptive forces by identifying and analyzing the execution of change toward desired business vision and outcomes. EA delivers value by presenting business and IT leaders with signature-ready recommendations for adjusting policies and projects to achieve targeted business outcomes that capitalize on relevant business disruptions.
Enterprise Architecture Book of Knowledge (EABOK) definition
Enterprise Architecture (EA) is an organizational model; an abstract representation of an Enterprise that aligns strategy, operations, and technology to create a roadmap for success.
Fundamentals of Data Engineering definition
Enterprise architecture is the design of systems to support change in the enterprise, achieved by flexible and reversible decisions reached through careful evaluation of trade-offs.
Data Architecture
TOGAF definition
A description of the structure and interaction of the enterprise’s major types and sources of data, logical data assets, physical data assets, and data management resources.
DAMA definition
Identifying the data needs of the enterprise (regardless of structure) and designing and maintaining the master blueprints to meet those needs. Using master blueprints to guide data integration, control data assets, and align data investments with business strategy.
Fundamentals of Data Engineering definition
Data architecture is the design of systems to support the evolving data needs of an enterprise, achieved by flexible and reversible decisions reached through a careful evaluation of trade-offs.
“Architecture represents the significant design decisions that shape a system, where significant is measured by cost of change.”
- Grady Brooch
- good data architecture is flexible and easily maintainable, and it’s a living, breathing thing
Principles of Good Data Architecture
AWS Well-Architected Framework
- operational excellence
- security
- reliability
- performance efficiency
- cost optimization
- sustainability
Google Cloud’s Five Principles for Cloud-Native Architecture
- design for automation
- be smart with state
- favor managed services
- practice defense in depth
- always be architecting
Fundamentals of Data Engineering Principles
- Choose components wisely
- rely on common components already in use rather than reinventing the wheel
- common components must support robust permission and security to enable sharing of assets among teams
- Plan for Failure
- Everything fails, all the time
- availability - The percentage of time an IT service or component is in an operable state
- reliability - The system’s probability of meeting defined standards in performing its intended function during a specified interval
- recovery time objective - The maximum acceptable time for a service or system outage
- recovery point objective - the acceptable state after recovery
- Architect for Scalability
- scalable systems need to scale up to handle significant amounts of data
- also need to scale down to reduce costs
- can scale to zero to turn off when not in use
- Architecture is Leadership
- Strong leadership skills combined with high technical competence are rare and extremely valuable
In many ways, the most important activity of Architectus Oryzus is to mentor the development team, to raise their level so they can take on more complex issues.mImproving the development team’s ability gives an architect much greater leverage than being the sole decision-maker and thus running the risk of being an architectural bottleneck.
- Strong leadership skills combined with high technical competence are rare and extremely valuable
- Always Be Architecting
- deep knowledge of the baseline architecture (current state), develop a target architecture, and map out a sequencing plan to determine priorities and the order of architecture changes
- Build Loosely Coupled Systems
- system broken into many small components
- These systems interface with other services through abstraction layers, such as a messaging bus or an API. These abstraction layers hide and protect internal details of the service, such as a database backend or internal classes and method calls.
- As a consequence of property 2, internal changes to a system component don’t require changes in other parts. Details of code updates are hidden behind stable APIs. Each piece can evolve and improve separately.
- As a consequence of property 3, there is no waterfall, global release cycle for the whole system. Instead, each component is updated separately as changes and improvements are made.
- loosely coupled teams and technical systems allow for more efficient work
- Make Reversible Decisions
- one way doors – a door you can’t walk back out of
- two way doors – a door you can leave the same way you came in
- Prioritize Security
- hardened-perimeter: a strong firewall prevents intrusion, but security controls are lax within the perimeter
- zero trust: no trust within or without the firewall
- Embrace FinOps
FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value by helping engineering, finance,technology, and business teams to collaborate on data-driven spending decisions.
Major Architecture Concepts
- domain - the real-world subject area for which you’re architecting
- service - a set of functionality whose goal is to accomplish a task
- scalability - allows us to increase capacity of system to improve performance and handle demand
- elasticity - ability of scalable system to scale dynamically
- availability - percentage of time an IT service or component is in operable state
- reliability - system’s probability of meeting defined standards in performing its intended function during a specified interval
- horizontal scaling - add more machines to satisfy load and resource requirements
- vertical scaling - increase resources (CPU, disk, memory, I/O) to satisfy load requirements
- tightly coupled services - extremely centralized dependencies and workflows – every part of a domain and service is vitally dependent upon every other domain and service
- loosely coupled services - decentralized domains and services that do not have strict dependence on each other
- single tier - your database and application are tightly coupled, residing on a single server
- multitier - (also known as n-tier) architecture is composed of separate layers: data, application, business logic, presentation, etc. a three tier architecture consists of data, application logic, and presentation tiers
- shared nothing architecture - a single node handles each request, meaning other nodes do not share resources such as memory, disk, or CPU with this node or with each other
- shared disk architecture - share the same disk and memory accessible by all nodes
- technical coupling - architectural tiers
- domain coupling - the way domains are coupled together
- monolith - a single codebase running on a single machine that provides both the application logic and user interface
- microservices - comprises separate, decentralized, and loosely coupled services
- brownfield projects often involve refactoring and reorganizing an existing architecture and are constrained by the choices of the present and past
- greenfield projects - allows you to pioneer a fresh start, unconstrained by the history or legacy of a prior architecture
- strangler pattern - new systems slowly and incrementally replace a legacy architecture’s components – allows for surgical approach of deprecating one piece of system at a time, and for flexible and reversible decisions
- event-driven architecture events that are broadly defined as something that happened, typically a change in the state of something, consisting of event production, routing, and consumption
Types of Data Architecture
Data Warehouse
- A data warehouse is a central data hub used for reporting and analysis. Data in a data warehouse is typically highly formatted and structured for analytics use cases. It’s among the oldest and most well-established data architectures.
- The organizational data warehouse architecture organizes data associated with certain business team structures and processes. The technical data warehouse architecture reflects the technical nature of the data warehouse, such as MPP
two main characteristics
- Separates online analytical processing (OLAP) from production databases (online trans‐ action processing)
- centralizes and organizes data
- Extract, Load, Transform (ELT) - data gets moved more or less directly from production systems into a staging area in the data warehouse
- cloud data warehouse – things like Redshift, Google BigQuery and Snowflake (the latter two separate compute and storage pricing)
-
data mart - a more refined subset of a warehouse designed to serve analytics and reporting, focused on a single suborganization, department, or line of business
- makes data more easily accessible to analysts and report developers
- provide an additional stage of transformation beyond that provided by initial ETL or ELT
Data Lake
- all data dumped in a central location
- led to dumping ground of data – data swamp, dark data, write once, read never (WORN)
- first generation of data lakes have largely gone out of style
Data Lakehouse
- The lakehouse incorporates the controls, data management, and data structures found in a data warehouse while still housing data in object storage and supporting a variety of query and transformation engines. In particular, the data lakehouse supports atomicity, consistency, isolation, and durability (ACID) transactions
The Modern Data Stack
main objective of the modern data stack is to use cloud-based, plug-and-play, easy-to-use, off-the-shelf components to create a modular and cost-effective data architecture. These components include data pipelines, storage, transformation, data management/governance, monitoring, visualization, and exploration.
Key outcomes of the modern data stack are self-service (analytics and pipelines), agile data management, and using open source tools or simple proprietary tools with clear pricing structures.
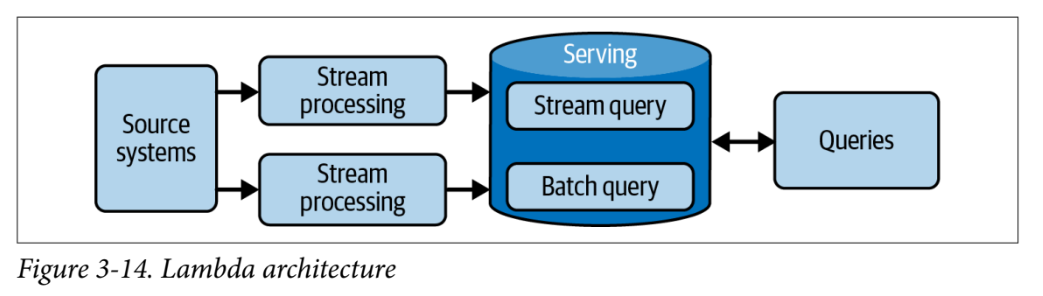
Lambda Architecture
In a Lambda architecture you have systems operating independently of each other—batch, streaming, and serving. The source system is ideally immutable and append-only, sending data to two destinations for processing: stream and batch.
Kappa Architecture
- response to shortcomings of Lambda architecture
- Jay Kreps proposed a system where stream-processing platform is the backbone of all data handling
- hasn’t been widely adopted despite introduced in 2014 – difficult to execute on and complicated to maintain
Dataflow Model
The core idea in the Dataflow model is to view all data as events, as the aggregation is performed over various types of windows. Ongoing real-time event streams are unbounded data. Data batches are simply bounded event streams, and the boundaries provide a natural window.
“batch is a special case of streaming”
IoT architecture
- data generated from devices (things) and sent to a destination
- devices - physical hardware connected to the internet and collect data and transmit to downstream destination
- iot gateway - hub for connecting devices and securely routing devices to appropriate destinations on the internet
Data Mesh
- see notes on Data Mesh
- response to sprawling, monolithic data platforms
- four key components
- Domain-oriented decentralized data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
4: Choosing Technologies Across the Data Engineering Lifecycle
Architecture is strategic; tools are tactical […] Architecture is the high-level design, roadmap, and blueprint of data systems that satisfy the strategic aims for the business. Architecture is the what, why, and when. Tools are used to make the architecture a reality; tools are the how.
Team Size and Capabilities
- There is a continuum of simple to complex technologies, and a team’s size roughly determines the amount of bandwidth your team can dedicate to complex solutions.
- take inventory of team’s skills, and use that to drive tool selection
Speed to Market
- choosing the right technologies that help you deliver features and data faster while maintaining high-quality standards and security
Interoperability
- describes how various tech or systems interact, connect, exchange data, etc.
- need to be aware of how simple it is to connect systems
Cost Optimization and Business Value
- budget and time and finite, and cost is major constraint in choosing the right arch
Total Cost of Ownership
- Total cost of ownership (TCO) is the total estimated cost of an initiative, including the direct and indirect costs of products and services utilized.
- direct costs - directly attributed to an initiative (salaries, AWS bill, etc.)
- indirect costs (overhead) - independent of the initiative, must be paid regardless
- capital expenses (capex) - require up-front investment, need to be paid today
- operational expenses (opex) - opposite of capex and gradual, over time
Total Opportunity Cost of Ownership
- total opportunity cost of ownership (toco) - cost of lost opportunities incur in choosing a tech, arch, or process
FinOps
If it seems that FinOps is about saving money, then think again. FinOps is about making money. Cloud spend can drive more revenue, signal customer base growth, enable more product and feature release velocity, or even help shut down a data center.
Today versus the future: immutable versus transitory technologies
- immutable tech - components that underpin cloud or languages or paradigms that have stood the test of time, eg. block storage, networking, servers, SQL, bash
- transitory tech - things that come and go, eg. Javascript front-end language
- should evaluate tools every two years, find the immutable tech and use that as base
Location
cloud
- much more flexible than on-prem, but you need to ensure compute optimization because pricing model is different than heavy upfront on-prem model
- The key to finding value in the cloud is understanding and optimizing the cloud pricing model
- Data gravity is real: once data lands in a cloud, the cost to extract it and migrate processes can be very high.
on-prem
- often default for companies, but less elastic and flexible than cloud
hybrid cloud
- both on-premise and in the cloud, depending on workload
multicloud
- deploying to multiple public clouds to take advantage of the best services across several clouds
Build versus buy
- argument for building is end to end control over solution and aren’t at the mercy of a vendor or open source community
- argument for buying is resource constraints and expertise
- should invest in building and customizing when doing so provides a competitive advantage for your business
Open Source Software (OSS)
- software distribution model where software and underlying code base made available for general use under specific licensing terms
- Community-managed OSS - vibrant use base and strong community. Need to assess mindshare, maturity, troubleshooting, project management, team, developer relations and community management, contributing, roadmap, self-hosting and maintenance, and giving back to the community to assess
- Commercial OSS - vendor will offer core of services for free and enhancements or managed services for a fee. Need to assess value, delivery model, support, releases and bug fixes, sales cycle and pricing, company finances, logos vs. revenue, and community support in choosing
- Proprietary Walled Gardens - two examples: independent companies and cloud-platform offerings – need to assess interoperability, mindshare and market share, documentation and support, pricing, and longevity
There’s excellent value in upskilling your existing data team to build sophisticated systems on managed platforms rather than babysitting on-premises servers.
Monolith versus modular
- monolith
- pros: easier to reason about, costs lower cognitive burden and context switching.
- cons: brittle, user-induced problems occur, multi-tenancy is a problem, and switching to a new system is painful
- modular
- pros: is easier to swap components to take advantage of fast moving landscape, limits team’s complexity and size
- cons: more to reason about, interoperability can be harder
While monoliths are attractive because of ease of understanding and reduced complexity, this comes at a high cost. The cost is the potential loss of flexibility, opportunity cost, and high-friction development cycles.
Serverless versus servers
-
Expect servers to fail Server failure will happen. Avoid using a “special snowflake” server that is overly customized and brittle, as this introduces a glaring vulnerability in your architec‐ ture. Instead, treat servers as ephemeral resources that you can create as needed and then delete. If your application requires specific code to be installed on the server, use a boot script or build an image. Deploy code to the server through a CI/CD pipeline.
-
Use clusters and autoscaling Take advantage of the cloud’s ability to grow and shrink compute resources on demand. As your application increases its usage, cluster your application servers, and use autoscaling capabilities to automatically horizontally scale your application as demand grows.
-
Treat your infrastructure as code Automation doesn’t apply to just servers and should extend to your infrastructure whenever possible. Deploy your infrastructure (servers or otherwise) using deployment managers such as Terraform, AWS CloudFormation, and Google Cloud Deployment Manager.
-
Use containers For more sophisticated or heavy-duty workloads with complex installed depen‐ dencies, consider using containers on either a single server or Kubernetes.
Optimization, performance, and the benchmark wars
- do your homework before relying on vendor benchmarks to choose
- Dewitt clause - forbids the publication of database benchmarks that the database vendor has not sanctioned
Always approach technology the same way as architecture: assess trade-offs and aim for reversible decisions.
5: Data Generation in Source Systems
- Analog data – occurs in real world, eg vocal speech, sign language, writing on paper, or playing an instrument creation
- Digital data – created by converting analog data to digital or native to a system
Source Systems - Main Ideas
Files and Unstructured Data
- files are universal medium of exchange
- structured (Excel, CSV), semistructured (JSON, XML, CSV), or unstructured (TXT, CSV)
APIs
- application programming interface - standard way of exchanging data between systems
Application Databases (OLTP Systems)
- online transaction processing (OLTP) system— a database that reads and writes individual data records at a high rate
- supports low latency and high concurrency
- ACID - atomicity,consistency, isolation, durability. Consistency means that any database read will return the last written version of the retrieved item. Isolation entails that if two updates are in flight concurrently for the same thing, the end database state will be consistent with the sequential execution of these updates in the order they were submitted. Durability indicates that committed data will never be lost, even in the event of power loss.
- running analytics on these machines works but is not scalable
Online Analytical Processing System (OLAP)
- OLAP to refer to any database system that supports high-scale interactive analytics queries
Change Data Capture (CDC)
- Change data capture (CDC) is a method for extracting each change event (insert, update, delete) that occurs in a database
- used to replicate between databases in real time
Logs
- captures information about events that occur in systems
- should capture who (human, system, service associated with event), what (the event and related metadata) and when (timestamp)
- logs can be binary, semi-structured (eg JSON) or plain text / unstructured
Messages and Streams
- message - raw data communicated across two or more systems
- stream - append-only log of event records
Types of Time
- always include timestamps for each phase through which an event travels
- ingestion time - when an event is ingested from source system into a message queue, cache, memory, etc.
- processing time - how long the data took to process, measured in seconds, minutes, hours
Types of Databases
relational database management system
- RDBMS - data is stored in a table of relations (rows) and each row contains multiple fields (columns)
- rows are typically stored as contiguous sequence of bytes on disk
- tables indexed by primary key - unique field for each row – indexing strategy is closely related to layout of table on disk
- tables can have foreign key - fields iwth values connected with the values of PKs of other tables, facilitating joins and allowing for complex schemas
- normalization - strategy for ensuring that data in records in not duplicated in multiple places
- typically ACID compliant
non-relational (nosql)
- not only sql - abandons relational paradigm
- far too many different types of nosql to cover in one section
key-value stores
- non-relational database that retrieves records using a key that uniquely identifies each record
- similar to hash map / dictionary
- good for caching data
- also help applications that require high-durability persistence
document stores
- specialized key-value store
- document is a nested object (like JSON)
- doesn’t support joins
- generally not ACID compliant
wide column
- optimized for storing massive amounts of data with high transaction rates and extremely low latency
- don’t support complex queries
- helpful for ad tech, IoT, real-time personalization apps
graph database
- explicitly store in mathematical graph structure (as a series of nodes and edges)
- Neo4j
- good fit when you want to analyze connectivity between elements
search
- nonrelational database used to search data’s complex and straightforward semantic and structural characteristics
- ideal for text search and log analysis
time series
- values organized by time
- eg. stock prices, logs, etc.
APIs
REST
- REST stands for representational state transfer. This set of practices and philosophies for building HTTP web APIs was laid out by Roy Fielding in 2000 in a PhD dissertation
- key principles are that interactions are stateless – there is no notion of a session or context
- if a REST call changes a systems state, these changes are global
However, low-level plumbing tasks still consume many resources. At virtually any large company, data engineers will need to deal with the problem of writing and maintaining custom code to pull data from APIs, which requires understanding the structure of the data as provided, developing appropriate data-extraction code, and determining a suitable data synchronization strategy.
GraphQL
- facebook query language for applicaiton data and an alternative to generic REST APIs
- built around JSON and allows for more expressive queries than REST
webhooks
- simple event-based data-transmission pattern
- when an event happens, it triggers a call to an HTTP endpoint hosted by data consumer
rpc and grpc
- remote procedure call (rpc) used in distributed computing – allows you to run a procedure on a remote system
- gRPC developed by google to utilize HTTP/2