Data Mesh: Delivering Data-Driven Value at Scale
Table of contents
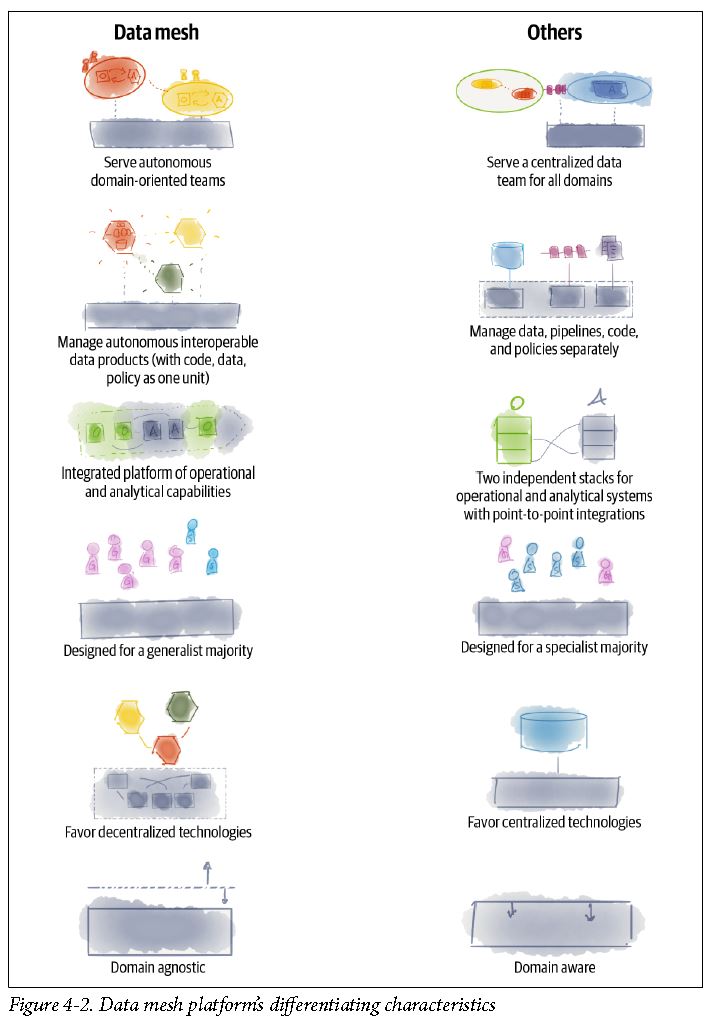
What is Data Mesh?
- Data mesh is a decentralized sociotechnical approach to share, access, and manage analytical data in complex and large-scale environments—within or across organizations
- data mesh looks to achieve these outcomes:
- Respond gracefully to change: a business’s essential complexity, volatility, and uncertainty
- Sustain agility in the face of growth
- Increase the ratio of value from data to investment1
organizational shifts required:
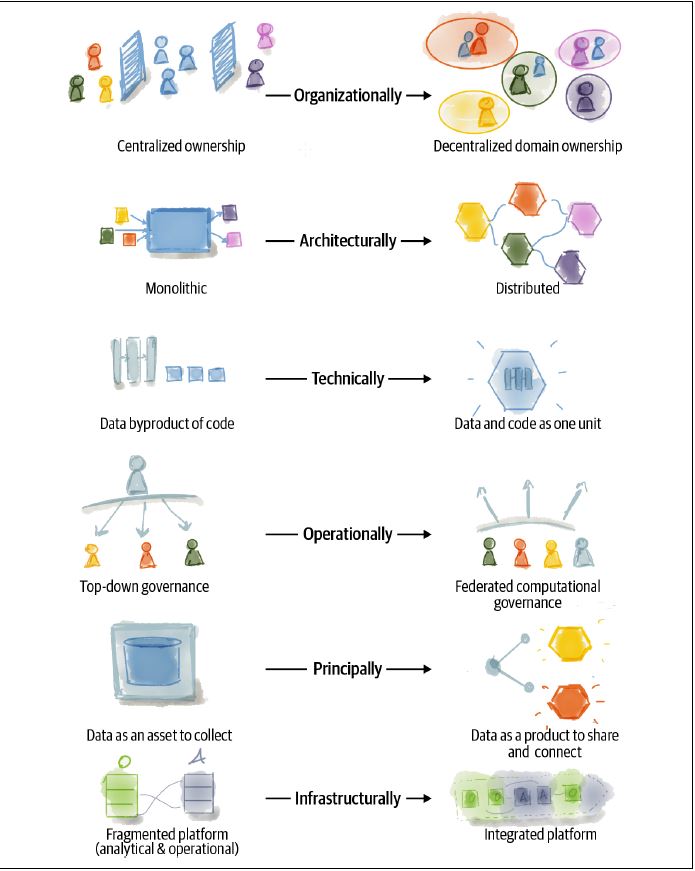
Data Mesh Model
- data mesh focuses on analytical data, as opposed to operational data
- operational data is “data on the inside”, private data of application
Data Principles
Interplay of Four Principles

Domain-Oriented Ownership
- underpinned by domain-driven design to find seams of organizational units to decompose data
- domain is a sphere of knowledge, influence, or activity
- bounded context - delimited applicability of a particular model that gives team members a clear and shared understanding of what has to be consistent and what can develop independently
- context mapping - define relationship between bounded contexts/independent models
three types of domain data
-
Source-aligned domain data
- Analytical data reflecting the business facts generated by the operational systems (native data product)
-
Aggregate domain data
- Analytical data that is an aggregate of multiple upstream domains.
-
Consumer-aligned domain data
- Analytical data transformed to fit the needs of one or multiple specific use cases (fit-for-purpose domain data)
Exposing analytical data directly from the operational database is an antipattern
- work with multiple models of shared entities rather than single source of truth, which is expensive and impediment to scale
- In data mesh, a data pipeline is simply an internal implementation of the data domain and is handled internally within the domain. It’s an implementation detail that must be abstracted from outside of the domain (26)
Data as a Product
- successful products have three common characteristics: they are feasible, valuable, and usable (from INSPIRED by Marty Cagan)
- product thinking to internal technology begins with establishing empathy with internal consumers (i.e., fellow developers), collaborating with them on designing the experience, gathering usage metrics, and continuously improving the internal technical solutions over time to maintain ease of use (31)
baseline usability attributes of data product
discoverable
data product itself intentionally provides discoverability information
addressable
provides a permanent and unique address to data user to programmatically or manually access
understandable
data product provides semantically coherent data with specific meaning
trustworthy & truthful
data product represents facts of business properly; need to know how closely data reflects reality of events that have happened SLOs:
- Interval of change: How often changes in the data are reflected
- Timeliness: The skew between the time that a business fact occurs and becomes available to the data users
- Completeness: Degree of availability of all the necessary information
- Statistical shape of data: Its distribution, range, volume, etc.
- Lineage: The data transformation journey from source to here
- Precision and accuracy over time: Degree of business truthfulness as time passes
- Operational qualities: Freshness, general availability, performance
natively accessible
- a data product needs to make it possible for various data users to access and read its data in their native mode of access
interoperable
- The key for an effective composability of data across domains is following standards and harmonization rules that allow linking data across domains
Some things to standardize
- Field type: A common explicitly defined type system
- Polysemes identifiers: Universally identifying entities that cross boundaries of data products
- Data product global addresses: A unique global address allocated to each data product, ideally with a uniform scheme for ease of establishing connections to different data products
- Common metadata fields: Such as representation of time when data occurs and when data is recorded
- Schema linking: Ability to link and reuse schemas—types—defined by other data products
- Data linking: Ability to link or map to data in other data products
- Schema stability: Approach to evolving schemas that respects backward compatibility
valuable on its own
- data product should be valuable without needing to be correlated or joined with other data products
secure
-
Data users access a data product securely and in a confidentiality-respecting manner. Data security is a must.
- Access control: Who, what, and how data users—systems and people—can access the data product
- Encryption: What kinds of encryption—on disk, in memory, or in transit—using which encryption algorithm, and how to manage keys and minimize the radius of impact in case of breaches
- Confidentiality levels: What kinds of confidential information, e.g., personally identifiable information, personal health information, etc., the data product carries
- Data retention: How long the information must be kept
- Regulations and agreements: GDPR, CCPA, domain-specific regulations, contractual agreements
two new roles needed for data mesh
- data product developer: responsible for developing, serving, and maintaining domain data products
- data product owner: accountable for success of domain’s data products in delivering value, growing data users, and maintaining life cycle of data products
- reframe receiving upstream data from ingestion to consumption – data is served already cleaned and processed
- success is measured through the value delivered to the users and not its size
Self-Serve Data Platform
The data platform is:
A collection of interoperable domain-agnostic services, tools, and APIs that enable cross-functional domain teams to produce and consume data products with lowered cognitive load and with autonomy.
The main responsibility of the data mesh platform is to enable existing or new domain engineering teams with the new and embedded responsibilities of building, sharing, and using data products end to end; capturing data from operational systems and other sources; and transforming and sharing the data as a product with the end data users.
- platform is used as shorthand for set of underlying data infrastructure capabilities – doesn’t mean single solution or single vendor
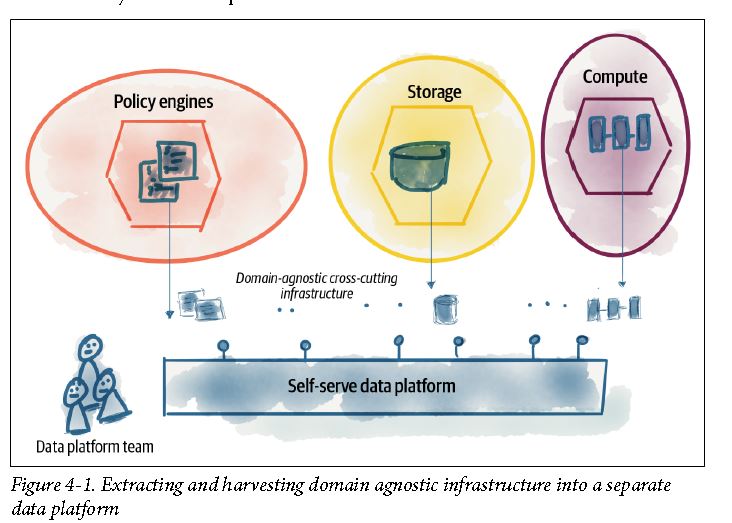
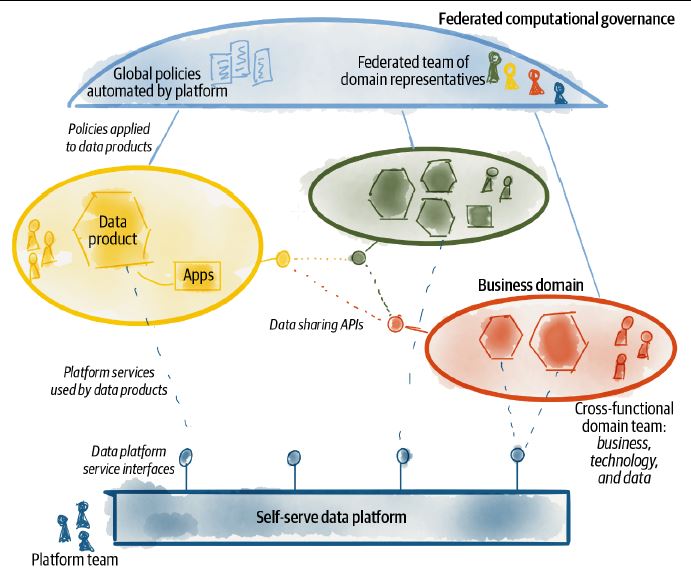
shift how we talk about data platform
- accommodate generalists (T shape, paint drip) rather than current industry requirement of specialists
key downsides of current data platform thinking
- cost is estimated and managed monolithically, not per isolated domain resources
- security and privacy management assume physical resources are shared under same account and don’t scale to isolated security context per data product
- A central pipeline (DAG) orchestration assumes management of all data pipelines centrally, which conflicts with independent pipeline
data platform objectives:
- enable autonomous teams to get value from data - platform enables product developer to concentrate on domain-specific aspects of data product development
- exchange value with autonomous and interoperable data products - mesh becomes organizational data marketplace
- accelerate exchange of value by lowering the cognitive load - abstracting complexity; should be able to declare structure of data, retention period, potential size, etc. – remove human intervention and manual steps
- scale out data sharing - embrace Unix philosophy
- support a culture of embedded innovation - rapidly building, testing, and refining ideas; need to free people from unnecessary work and accidental complexity
how to transition to self-servce data mesh platform
- design APIs and protocols first - start with interfaces platform exposes to its users
- prepare for a generalist approach - favor platform tech that fits better with natural style of programming (not something that creates another DSL)
- do an inventory and simplify - take a look at what you already have
- create higher-level APIs to manage data products - platform must introduce higher level of APIs that deal with data product as an object
- build experiences, not mechanisms - shift articulation of platform from mechanisms it includes to the experiences it enables
- begin with simplest foundation, then harvest to evolve - data platform is emergent, designed and brought to life incrementally by many
Federated Computational Governance
Federated and computational governance is a decision-making model led by the federation of domain data product owners and data platform product owners, with autonomy and domain-local decision-making power, while creating and adhering to a set of global rules
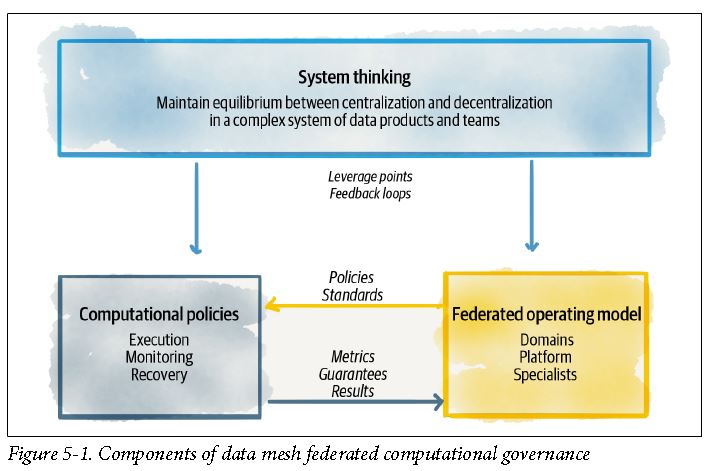
Apply Systems Thinking to Data Mesh Governance
- data mesh requires a governance model that embraces systems thinking. Systems thinking, as described by Peter Senge, is the discipline of “seeing the whole,” shifting our focus “from parts to the organization of parts, recognizing interaction of the parts are not static and constant, but dynamic processes.”
- mesh is more than the sum of its parts
- the art of governing a data mesh ecosystem is in maintaining an equilibrium between local (domain) optimization and global (the mesh) optimization
- need to continuously adjust behavior using leverage points (small change lead to large shift in behavior) and feedback loops (system structures that either balance or reinforce a change in state of system)
- embrace dynamic topology as default state
- utilize automation and distributed architecture
Apply Federation to the Governance Model
Federated Team - team that decides policies implemented, how platform supports these policies computationally, how data products adopt policies
- created of domain representatives, data platform representatives, subject matter experts, and facilitators and managers
Guiding Values - clarity on value system that guides how decisions are made
- localize decisions and responsibility close to the source
- identify cross-cutting concerns that need a global standard
- globalize decisions that facilitate interoperability
- identify consistent experiences that need a global standard
- execute decisions locally
Policies - output of a system governance, between local and global effect
Incentives - what incentives to use to motivate as leverage points, can be local or global
Apply Computation to the Governance Model
Standards as Code behavior, interfaces, and data structure that is expected to be implemented in a consistent way across all data products
- data product discovery and observability interfaces
- data product data interfaces
- data and query modeling language
- lineage modeling
- polysemes identification modeling
Policies as Code
- data privacy and protection
- data localization
- data access control and audit
- data consent
- data sovereignty
- data retention
Automated Tests Automated Monitoring
data mesh governance heavily relies on embedding the governance policies into each data product in an automated and computational fashion. This of course heavily relies on the elements of the underlying data platform, to make it really easy to do the right thing.
The continuous need for trustworthy and useful data across multiple domains to train ML-based solutions will be the ultimate motivator for the adoption of data mesh governance and doing the right thing.
Why Data Mesh?
- great expectations of data - diverse and wide applications of ML and analytics
- great divide of data - complexity risen from fragmentation of operational and analytical data
- scale - large scale data source proliferation
- business complexity and volatility - continuous change and growth of business
- discord between data investments and returns - expensive data solutions lacking impact
Data mesh learns from the past solutions and addresses their shortcomings. It reduces points of centralization that act as coordination bottlenecks. It finds a new way of decomposing the data architecture without slowing the organization down with synchronizations. It removes the gap between where the data originates and where it gets used and removes the accidental complexities—aka pipelines—that happen in between the two planes of data. Data mesh departs from data myths such as a single source of truth, or one tightly controlled canonical data model.
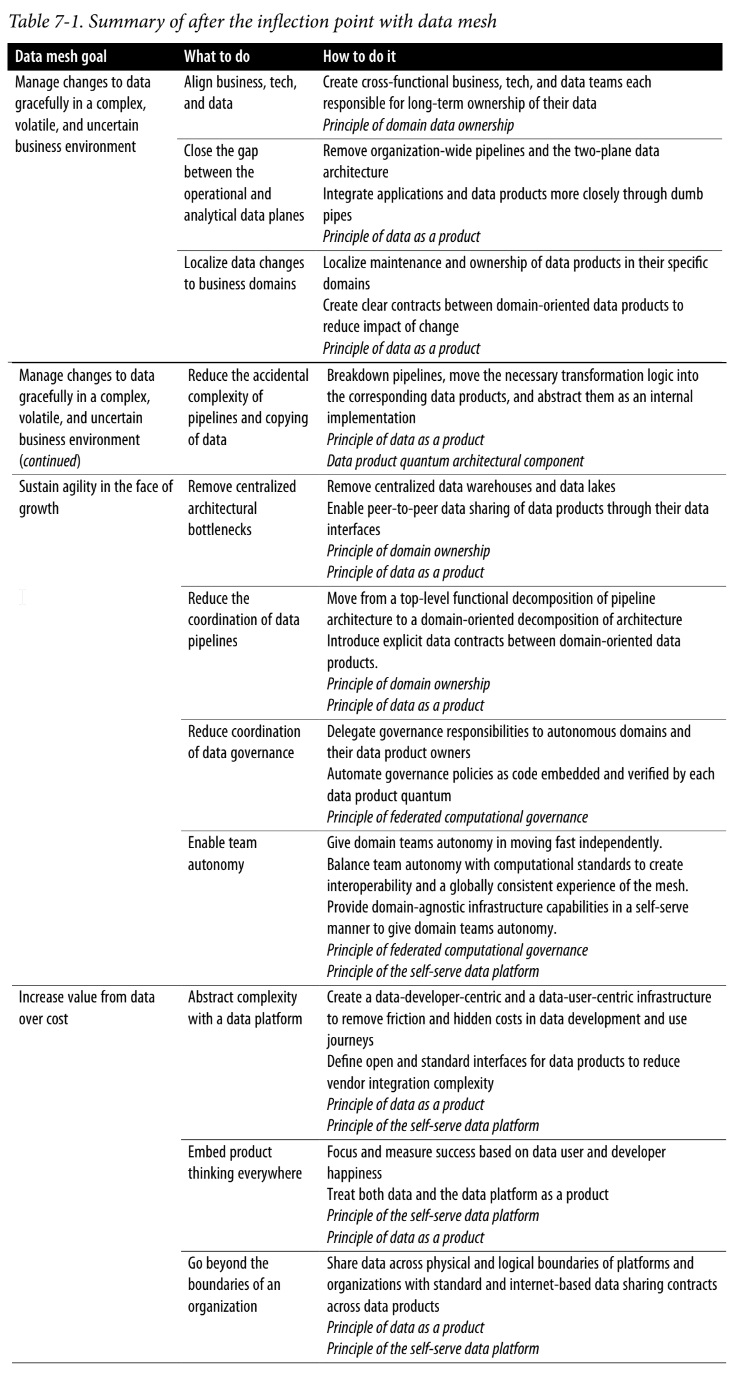
Progression of Data Architecture
First Generation: Data Warehouse Architecture
- Extracted from many operational databases and sources
- Transformed into a universal schema—represented in a multidimensional and time-variant tabular format
- Loaded into the warehouse tables
- Accessed through SQL-like queries
- Mainly serving data analysts for reporting and analytical visualization use cases
Second Generation: Data Lake Architecture
- introduced in 2010 as response to challenge of data warehouse in satisfying data scientists who wanted data in original format
- Data is extracted from many operational databases and sources.
- Data represents as much as possible of the original content and structure.
- Data is minimally transformed to fit the popular storage formats, e.g., Parquet, Avro, etc.
- Data—as close as possible to the source schema—is loaded to scalable object storage.
- Data is accessed through the object storage interface—read as files or data frames, a two-dimensional array-like structure.
- Data scientists mainly access the lake storage for analytical and machine learning model training.
- Downstream from the lake, lakeshore marts are created as fit-for-purpose data marts.
- Lakeshore marts are used by applications and analytics use cases.
- Downstream from the lake, feature stores are created as fit-for-purpose columnar data modeled and stored for machine learning training.
Third Generation: Multimodel Cloud Architecture
- Support streaming for near real-time data availability with architectures such as Kappa.
- Attempt to unify batch and stream processing for data transformation with frameworks such as Apache Beam.
- Fully embrace cloud-based managed services and use modern cloud-native implementations with isolated compute and storage. They leverage the elasticity of the cloud for cost optimization.
- Converge the warehouse and lake into one technology, either extending the data warehouse to include embedded ML training, or alternatively building data warehouse integrity, transactionality, and querying systems into data lake solutions.
Characteristics of Current Data Architecture
- monolithic architecture - 1) ingest data, 2) cleanse enrich and transform data, and 3) serve data
- monolithic technology
- monolithic organization - central data team, conway’s law
- centrally owned
- technically partitioned (rather than domain partitioned) – partitioning is orthogonal to axes of change and slows releases
How to Design Data Mesh
Data Mesh Architectural Components
Domain
- Systems, data products, and a cross-functional team aligned to serve a business domain function and outcomes and share its analytical and operational capabilities with the wider business and customers.
- This is a well-established concept.
Domain analytical data interfaces
- Standardized interfaces that discover, access, and share domain-oriented data products.
- At the time of writing, the implementation of these APIs is custom or platform specific.
- The proprietary platforms need to offer open interfaces to make data sharing more convenient and interoperable with other hosting platforms.
Domain operational interfaces
- APIs and applications through which a business domain shares its transactional capabilities and state with the wider organization.
- This concept has mature implementations.
- It is supported by de facto standards such as REST, GraphQL, gRPC, etc.
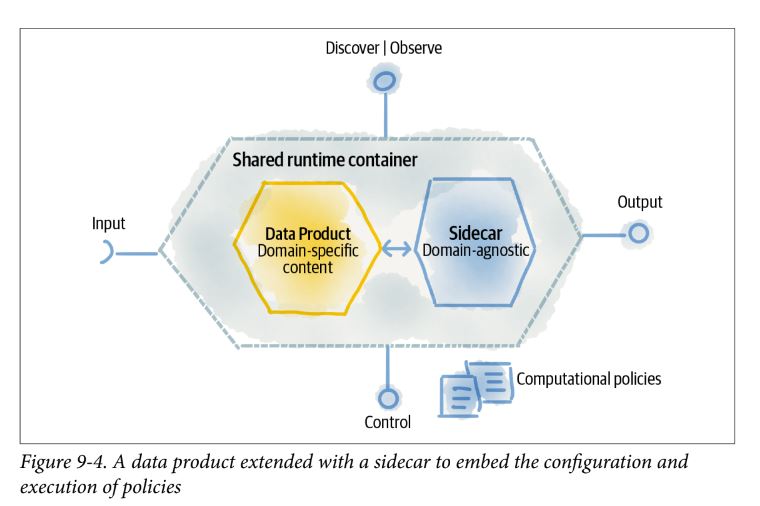
Data (product) quantum
- Data product implemented as an architecture quantum that encapsulates all the structural components it needs to do its job —- code, data, infrastructure specifications, and policies.
- It is referred to in architectural discussions. It is used interchangeably with data products.
- At the time of writing this is an experimental concept with custom implementations.
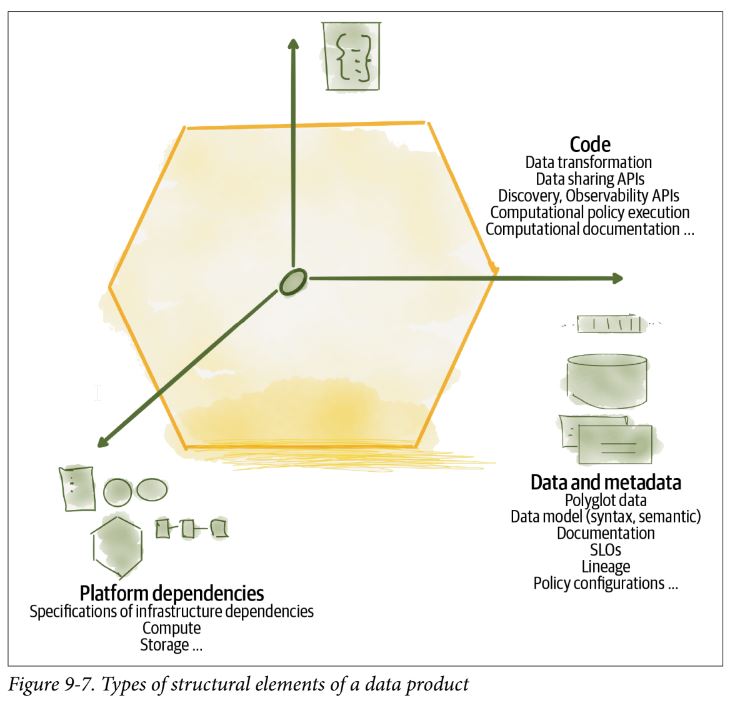
Data (product) container
- A mechanism to bundle all the structural components of a data product, deployed andmrun as a single unit with its sidecar.
- At the time of writing this is an experimental concept with custom implementations.
Data product sidecar
The accompanying process to the data product. It runs with the context of a data product container and implements cross-functional and standardized behaviors such as global policy execution.
- At the time of writing this is an experimental concept with custom implementations.
Input data port
- A data product’s mechanisms to continuously receive data from one or multiple upstream sources.
- At the time of writing this has custom implementations with existing event streaming and pipeline management technologies.
Output data port
- A data product’s standardized APIs to continuously share data.
- At the time of writing this has vendor-specific custom implementations.
- A mature implementation of the concept requires open data sharing standards with support for multiple modes of access to temporal data.
Discovery and Observability APIs
- A data product’s standard APIs to provide discoverability information —- to find, address, learn, and explore a data product—and observability information such as lineage, metrics, logs, etc.
- At the time of writing custom implementations of these APIs have been built.
- A mature implementation requires open standards for discoverability and observability information modeling and sharing. Some standards are currently under development.
Control port
- A data product’s standard APIs to configure policies or perform highly privileged governance operations.
- At the time of writing this concept is experimental.
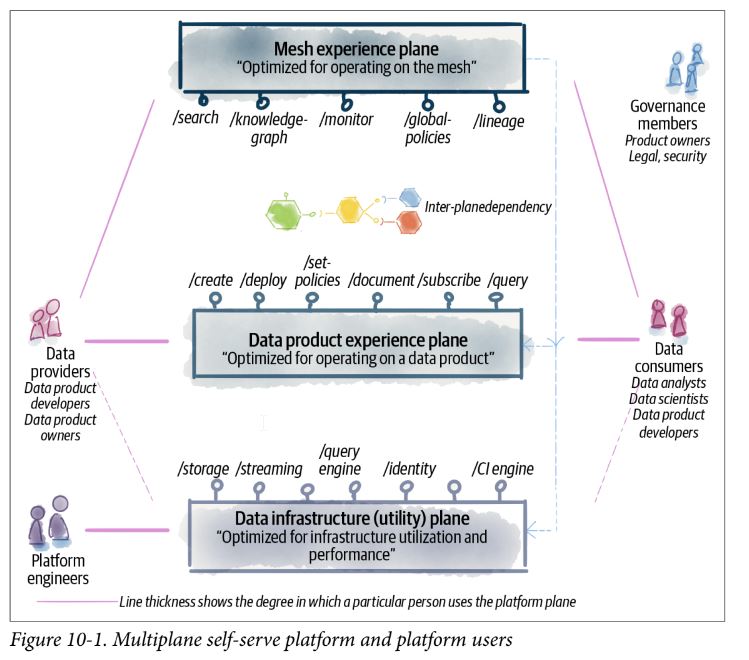
Platform plane
- A group of self-serve platform capabilities with high functional cohesion surfaced through APIs.
- This is a general concept and well established.
Data infrastructure utility plane
- Atomic services to provision and manage physical resources such as storage, pipeline orchestration, compute, etc.
- At the time of writing the services that constitute the infrastructure plane are mature and provided by many vendors with support for automated provisioning.
Data product experience plane
- Higher-level abstraction services that operate directly with a data product and enable data product producers and consumers to create, access, and secure a data product, among other operations that run on a data product.
- At the time of writing, custom implementation of services constituting a data product experience plane has been implemented. No reference implementation publicly exists.
Mesh experience plane
- Services that operate on a mesh of interconnected data products such as searching for data products and observing the data lineage across them.
- At the time of writing, custom implementations of some of the services constituting a mesh experience plane, such as discovery and search services, have been implemented. No reference implementation publicly exists.
Data Plane User Journeys/Personas
- data product developers - from generalist developers to specialist data engineers who 1) incept, explore, bootstrap, and source, 2) build, test, deploy and 3) maintain, evolve, and retire a data product
- data product consumers - they need access and use data to do their job
- data product owners - responsible for delivering and evangelizing successful data products for their specific domains
- data governance members - have a collective set of responsibilities to assure the optimal and secure operation of the mesh as a whole
- data platform product owner - responsible for delivering the platform services as a product with the best user experience
- data platform developers - build and operate the data platform (as well as use it)
Data Product Affordances
The term affordance refers to the relationship between a physical object and a person (or for that matter, any interacting agent, whether animal or human, or even machines and robots). An affordance is a relationship between the properties of an object and the capabilities of the agent that determine just how the object could possibly be used. A chair affords (“is for”) support and, therefore, affords sitting. Most chairs can also be carried by a single person (they afford lifting), but some can only be lifted by a strong person or by a team of people. If young or relatively weak people cannot lift a chair, then for these people, the chair does not have that affordance, it does not afford lifting. The presence of an affordance is jointly determined by the qualities of the object and the abilities of the agent that is interacting. This relational definition of affordance gives considerable difficulty to many people. We are used to thinking that properties are associated with objects. But affordance is not a property. An affordance is a relationship. Whether an affordance exists depends upon the properties of both the object and the agent.
- affordances can be thought of as properties of the data product
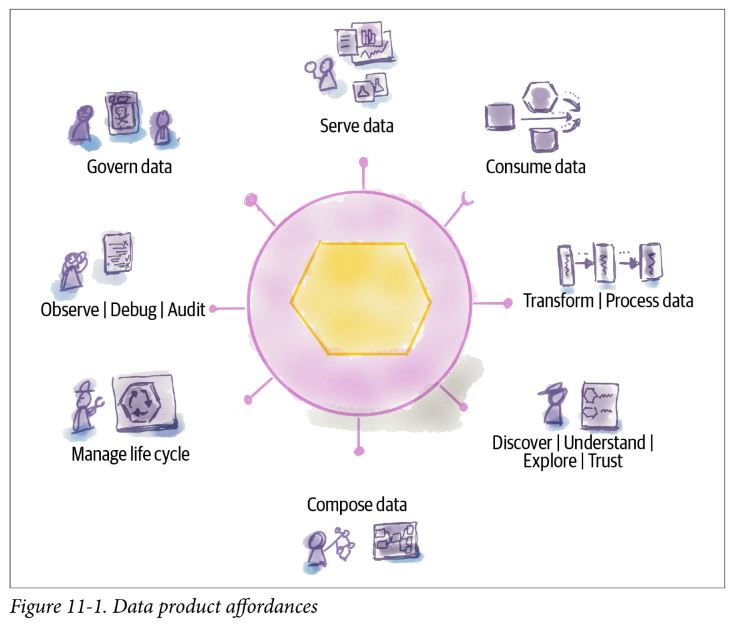
- design for change - data products need to respond gracefully to change
- design for scale - data product must result in a scale-out mesh
- design for value - data product must put delivering value to its consumers with the least amount of friction at its heart
- there is no central orchestrator of pipelines, aware of global configuration – for globalized behavior the sidecar pattern is used
Serve Data
- The data product shares immutable and bitemporal data, available through clearly defined read-only interfaces supporting multiple modes of access.
- The data product affords a diverse set of data product users to access data for training machine learning models, generating reports, data analysis and exploration, and building data-intensive applications.
- It does not afford transactional and operational applications that require updating or deleting data to maintain their current state.
Consume Data
- The data product consumes data from upstream sources of a variety of types.
- The data product affords consuming data from its collaborating operational application, other data products, or external systems.
- The data product only affords consuming data from the sources it identifies and configures through the platform.
- It does not afford consuming data from sources it does not identify and configure.
Transform Data
- The data product processes and transforms input data into new data that it then serves.
- The data product affords data product developers with multiple modes of transformation computation.
- The transformation can be program code, a machine learning model, or a complex query running inference.
- The transformation can generate new data or remodel or improve the quality of input data.
Discover | Understand | Explore | Trust
- The data product serves APIs and information that affords data product users to discover, explore, understand, and trust it.
- data quality metrics – not to signal data is good or bad, just useful to communicate threshold of guarantees
- accuracy - how closely the data represents the true value of the attribute in the real-world context
- completeness - the degree of data representing all properties and instances of the real-world context
- consistency - the degree of data being free of contradicitons
- precision - the degree of attribute fidelity
Compose Data
- The data product affords data product users to compose, correlate, and join its data with other data products.
- The data quantum affords programmatic data composability by performing set (table or graph) operations computationally.
- The data product does not afford data composability to systems that demand a single and tightly coupled data schema (e.g., SQL schema) shared across multiple data products.
Manage Life Cycle
- The data product affords data product users to manage its life cycle.
- It provides a set of build-time and runtime configuration and code so that data product developers can build, provision, and maintain it.
Observe | Debug | Audit
- The data product affords data product users to monitor its behavior, debug its issues, and audit it.
- It provides programmatic APIs to provide the necessary information such as data processing logs, lineage, runtime metrics, and access logs.
- use cases for observability via logs, traces, and metrics:
- monitor the operational health of the mesh
- debug and perform postmortem analysis
- perform audits
- understand data lineage
Govern
- The data product affords data users (governance group, data product developers) and the mesh experience plane (administrative and policy controls) a set of APIs and computational policies to self-govern its data.
- It enables the build-time configuration of its governing policies and runtime execution of them at the point of access to data, read or write. For example, it maintains data security by controlling access to its data and protects privacy and confidentiality through encryption.
Getting Started with Data Mesh
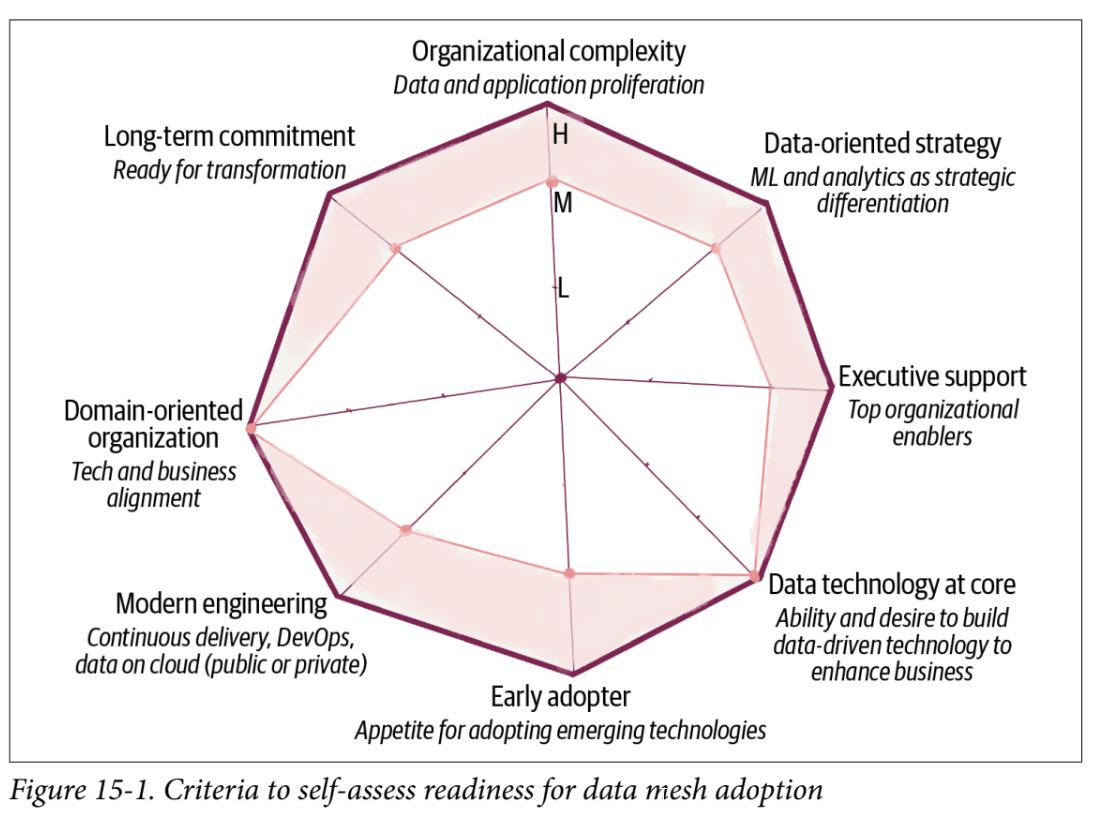
- organizational complexity - orgs that experience scale and complexity where existing data warehouse or lake solutions are blockers
- data-oriented strategy - orgs planning to get value from data at scale
- executive support - demands motivating the org to change how people work
- data technology at core - orgs that use data and AI as a competitive advantage
- early adopter - demand spirit of experimentation, taking risks, failing fast, learning, and evolving
- modern engineering - tech that enforce centralized data modeling, control, storage don’t lend themselves well to data mesh
- domain-oriented organization - tech organized around business domains
-
long-term commitment - adoption of data mesh is a transformation and a journey
- data mesh requires transformational change as a component of a larger data strategy
business-driven execution has benefits:
- continuous delivery and demonstration of value and outcome
- rapid feedback from the consumers
- reducing waste - create only whats needed
challenges:
- building point-in-time solutions - might develop platform capabilities that are not extensible
- delivering to tight business deadlines
- project-based budgeting - projects as sole source of investment for building platform services
guidelines for business-driven execution
- start with complementary use cases - allows avoiding point solutions
- know and prioritize the data consumer and provider personas
- start with use cases that have minimal dependencies on the platform’s missing features
- create long-term ownership and budgeting for platform services and data products
- works best as a multi-phase evolution, built iteratively (avoid rigid up-front plans)
- use fitness functions to measure evolution towards goal
- fitness function - an objective function used to summarize how close a prospective design solution is to achieving its set aims.
Changing Culture
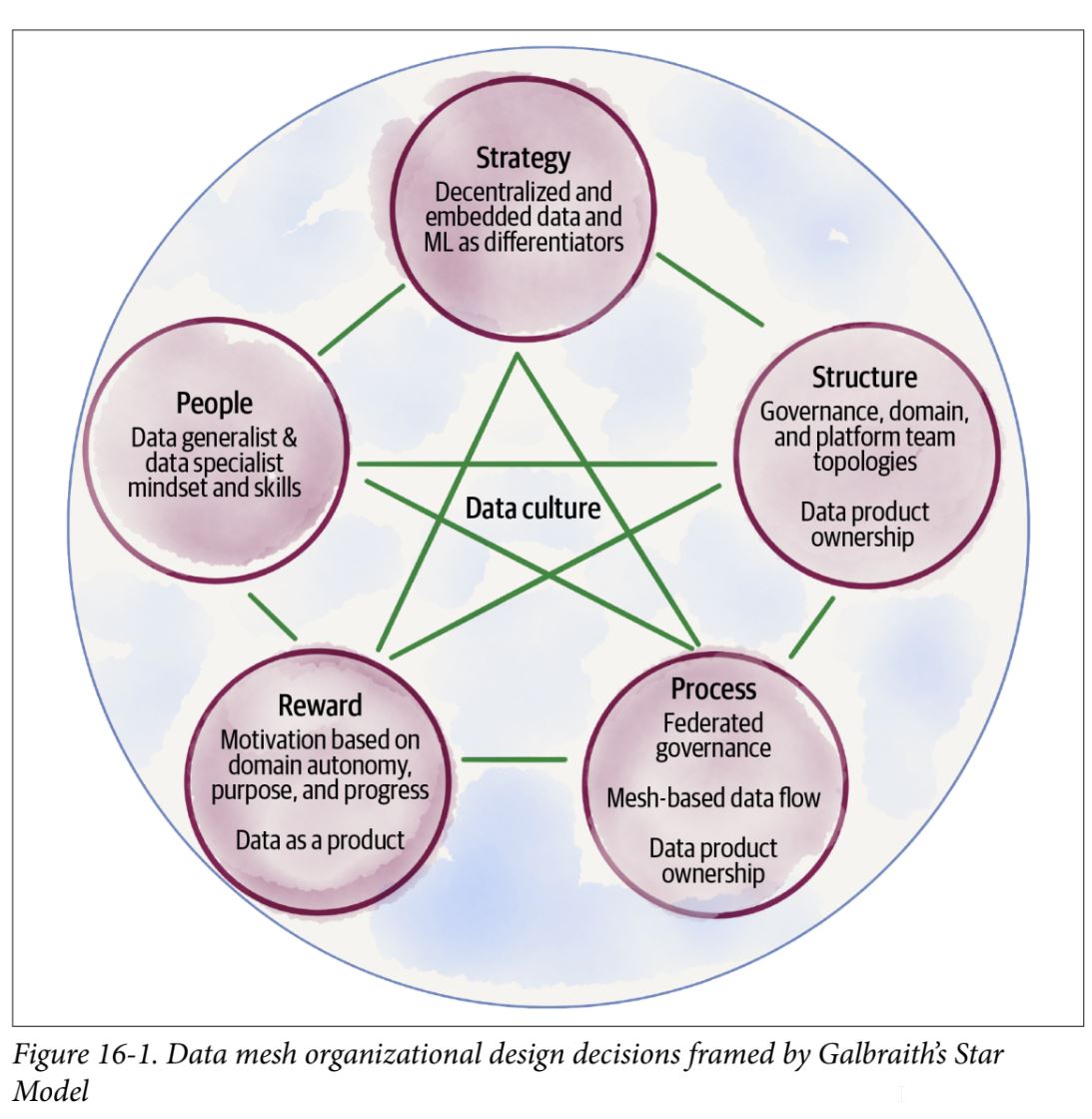
- Deploy a movement-based organizational change – start small and move fast to show value, get buy-in, and gather momentum toward a sustainable and scaled change