AWS for Solution Architects
Table of contents
- 1: Understanding AWS Cloud Principles and Key Characteristics
- 2: Leveraging the Cloud for Digital Transformation
- 3: Storage in AWS
- 4: Cloud Computing
- 5: Selecting the Right Database Service
- 6: Amazon Athena
- 7: AWS Glue
- 8: Best Practices for Security, Identity, and Compliance
- 9: Severless and Container Patterns
- 10: Microservice and Event-Driven Architectures
1: Understanding AWS Cloud Principles and Key Characteristics
The cloud is just a bunch of servers and other computing resources managed by a third-party provider in a data center somewhere
Cloud Elasticity
One important characteristic of the leading cloud providers is the ability to quickly and frictionlessly provision resources. In a cloud environment, instead of needing potentially months to provision your servers, they can be provisioned in minutes.
Another powerful characteristic of a cloud computing environment is the ability to quickly shut down resources and, importantly, not be charged for that resource while it is down.
elasticity is the ability of a computing environment to adapt to changes in workload by automatically provisioning or shutting down computing resources to match the capacity needed by the current workload.
Cloud Virtualization
Virtualization is the process of running multiple virtual instances on top of a physical computer system using an abstract layer sitting on top of actual hardware.
A hypervisor is a computing layer that enables multiple operating systems to execute in the same physical compute resource. These operating systems running on top of these hypervisors are Virtual Machines (VMs).
Definition of the Cloud
The cloud computing model is one that offers computing services such as compute, storage, databases, networking, software, machine learning, and analytics over the internet and on demand. You generally only pay for the time and services you use.
The Five Pillars of a Well-Architected Framework
Pillar 1: Security
- Always enable traceability.
- Apply security at all levels.
- Implement the principle of least privilege.
- Secure the system at all levels: application, data, operating system, and hardware.
- Automate security best practices
Pillar 2: Reliability
- Continuously test backup and recovery processes.
- Design systems so that they can automatically recover from a single component failure.
- Leverage horizontal scalability whenever possible to enhance overall system availability.
- Use automation to provision and shutdown resources depending on traffic and usage to minimize resource bottlenecks.
- Manage change with automation.
Pillar 3: Performance Efficiency
- Democratize advanced technologies.
- Take advantage of AWS’s global infrastructure to deploy your application globally with minimal cost and to provide low latency.
- Leverage serverless architectures wherever possible.
- Deploy multiple configurations to see which one delivers better performance.
Pillar 4: Cost Optimization
- Use a consumption model.
- Leverage economies of scale whenever possible.
- Reduce expenses by limiting the use of company-owned data centers.
- Constantly analyze and account for infrastructure expenses
Pillar 5: Operational Excellence
Measured across three dimensions:
- Agility
- Reliability
- Performance
- Provision infrastructure through code (for example, via CloudFormation).
- Align operations and applications with business requirements and objectives.
- Change your systems by making incremental and regular changes.
- Constantly test both normal and abnormal scenarios.
- Record lessons learned from operational events and failures.
- Write down and keep standard operations procedures manual up to date.
2: Leveraging the Cloud for Digital Transformation
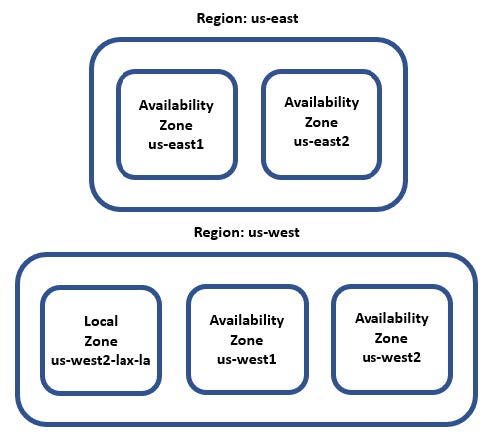
Regions, Availability Zones, and Local Zones
AWS breaks their infrastructure down into parts:
- AWS Regions exist in separate geographic areas, and are made up of several isolated and independent data centers
- Availability Zones (AZ) are the data centers within a region
- Local Zones are mini AZs that provide core services that are latency sensitive
Regions
Regions are separate from each other and this promotes availability, fault tolerance, and stability.
Sometimes a service might not be generally available (GA) and is only in one region.
Some services are available globally and aren’t region specific Simple Storage Service (S3), Identity Management Service (IAM), and other services have inter-Region fault tolerance – e.g., RDS with read replicas
AWS has a dedicated region just for the government called AWS GovCloud.
Availability Zones
The same as a data center. Have multiple power sources, redundant connectivity, and redundant resources.
AZs within Regions are interconnected, which gives you fully redundant, high bandwith, low latency, scalable, encrypted, and dedicated connections.
Some services allow you to choose AZ while some are automatically assigned.
Local Zones
Allow low latency for select services. Like a subset of an AZ, but doesn’t have all the services available in an AZ.
Use Case: Applications which require single-digit millisecond latencies to your end-users, latency-sensitive applications
Direct Connect
A low-level infrastructure service that enables AWS customers to set up a dedicated network connection between their on-premise facilities and AWS that allows bypassing public internet.
Does not provide encryption in transit, so a separate service (e.g., AWS Site-to-Site VPN) can be paired to encrypt data in transit.
Uses IEEE 802.1Q (I triple E eight oh two dot 1 Q) to create VLANs.
Can reduce costs when workloads require high bandwith by:
- transfers data from on-prem to cloud, directly reducing ISP commitments
- costs to transfer data are billed using AWS Direct Connect transfer rate rather than internet data transfer rates, which is typically lower
Implementing a Digital Transformation Program
Moving legacy on-prem to cloud Some questions to ask:
- should we do bare minimum, or is it an opportunity to refactor, enhance, and optimize workloads?
- should the transformation be purely technological, or should we transform business processes too?
Rehost
lift and shift least amount of work, services are simply migrated as is, and any problems with existing applications will come along during the migration.
Use case: If you are confident your processes and workflows are solid and don’t need to change.
Refactor
Not only migrating services, but changing their underlying architecture.
Use case: You are comfortable with current application but want to take advantage of certain cloud advantages and functionality, such as database failover.
Revise
Modify, optimize, and enhance existing applications and code base before migrating, then you can rehost or refactor. Good for maintaining business continuity and creating business enhancements, but sub-optimal sometimes because of cost of changing and testing code upfront.
Use case: If you know your applications are sub-optimal and need to be revised anyway.
Rebuild
Completely rewrite and rearchitect the existing applications, which will be considerable work and considerable cost, and might contribute to vendor lock-in.
Use case: If the most radical change is needed.
Replace
Get rid of applications but replace with SaaS alternatives, which may or may not be more expensive than rebuilding depending on talent pool. Learning curve and development life cycle is shortened, but software will require additional licenses.
Use case: If there is a commercially available software as a service available and your talent pool is short.
Migration Assessment Tools
- AWS Migration Hub: central repository to keep track of a migration project
- AWS Application Discovery Service: automates the discovery and inventory tracking of different infrastructure resources, such as servers, and any dependencies among them
- AWS Migration Pattern Library: collection of migration templates and design patterns that can assist in the comparison of migration options and alternatives
- CloudEndure Migration: simplifies cloud migration by automating many of the steps necessary to migrate to the cloud
- AWS Data Migration Service: facilitate the migration of data from your on-premises databases to the cloud, e.g., into Amazon RDS
Digital transformation involves using the cloud and other advanced technology to create new or change existing business flows. It often involves changing the company culture to adapt to this new way of doing business. The end goal of digital transformation is to enhance the customer experience and to meet ever-changing business and market demand.
Digital Transformation Tips
-
ask the right questions
- how can we be doing what we do, faster and better?
- how can we change what we do to better serve our customers
- can we eliminate certain lines of business, departments, and processes
- what are the desired business outcomes when interfacing with customers
-
get leadership buy-in
- need buy-in from C-Suite
- can still do Proof of Concept work to prove value
-
clearly delineate goals and objectives
- what are you trying to achieve with migration and ruthlessly pursue that
-
apply agile methodology to digital transformation
- small, iterative improvement to realize value earlier, as opposed to waterfall
- look for singles, not home runs
- pick low-hanging fruit and migrate those workloads first, which will build momentum for other, harder tasks later
-
encourage risk-taking
- fail, but fail fast and try different things
- it is better to disrupt yourself than someone else do it
-
clear delineation of roles and responsibilities
- make sure all team members are aligned on their responsibilities
Digital Transformation Pitfalls
-
lack of commitment from the C-Suite
- might fail to provide vision and path to success or resources
-
not having the right team in place
- inexperience with cloud migration, you don’t know what you don’t know
-
internal resistance from the ranks
- people whose roles may be diminished would resist
-
going too fast
- moving too much at once without doing any proof of concept work
-
going too slow
- spending forever planning or migrating small things might make interest wane
-
outdated rules and regulations
- some industries are difficult to disrupt because older regulations exist, e.g., real estate requiring wet signatures
3: Storage in AWS
Amazon Elastic Block Storage (EBS)
hard drive for a server, and can easily detach from one server and attach to another, and useful for persistent data, in comparison to the ephemeral data of an EC2 instance. replicated by design, so no need to set up a RAID or another redundancy strategy.
Snapshots are iterative and stored on S3. They can be compressed, mirrored, transferred across AWS AZs (by Amazon Data Lifecycle Manager). Stored as Amazon Machine Images (AMI) so they can be used to launch an EC2 instance.
using Elastic File Storage (EFS), you can attach the block storage device to multiple EC2 instances
Amazon provides 99.999% availability
-
General-purpose Solid State Devices (SSDs)
- solid balance of cost and performance
- useful for virtual desktops, development and staging environments, application developmenet
-
Provisioned IOPS SSD
- provisioned inputs and outputs per second ideal for mission critical apps
- business applications, production databases
-
Throughput Optimized HDD
- good value and reasonable cost for workloads that need high performance and high throughput
- big data, log processing, streaming applications, data warehouse applications
-
Cold HDD
- optimize cost with large volumes of data
- data the is infrequently accessed
Amazon Elastic File System (EFS)
Implements a fully managed Network File System (NFS), and several EC2 instances can be mounted to an EFS volume at the same time.
Often used for:
- hosting content management systems
- hosting CRM applications that need to be hosted within an AWS data center but need to be managed by customer
Simple Storage Service (S3)
Object storage, and AWS’s second oldest product, right after EC2. Time To First Byte (TTFB) used to measure performance of a service.
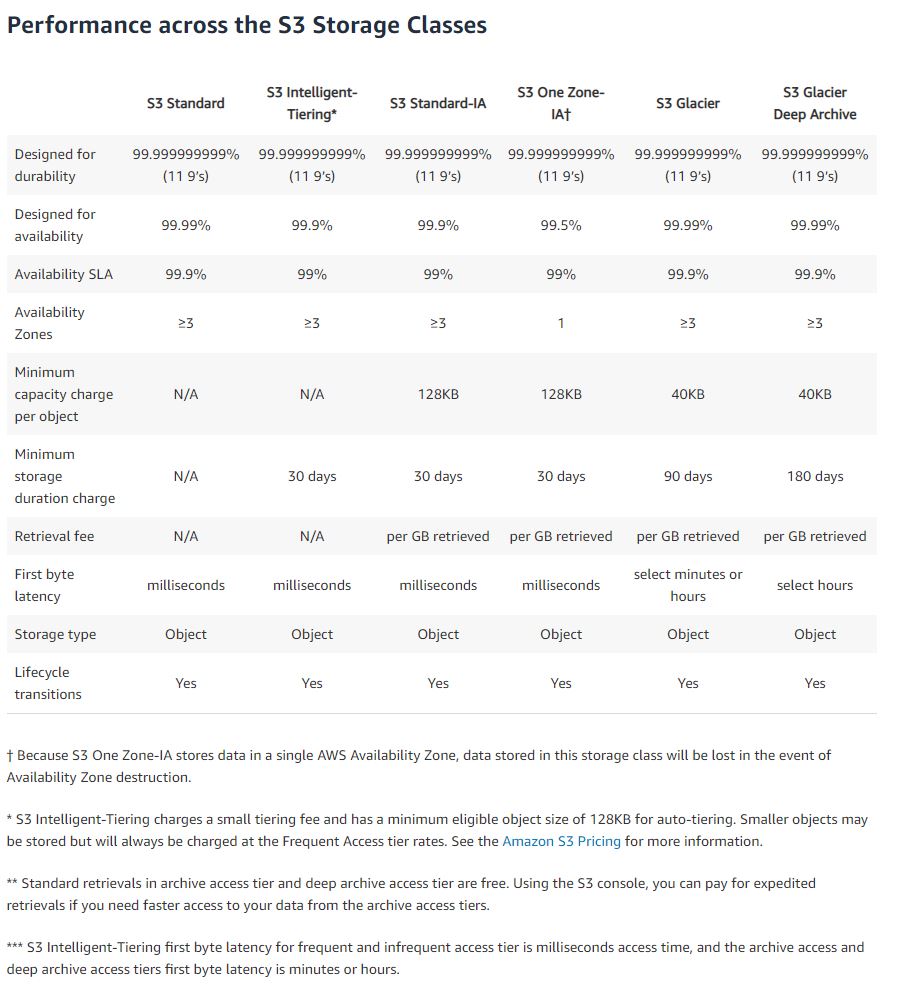
Comparison of Storage

Enhancing S3 performance
You should be cognizant of where users are going to access content and design around that.
One way is to scale horizontally – S3 allows as many connections to an S3 bucket as possible.
CloudFront
A Content Delivery Network (CDN) that caches S3 content to be served across disperse geographic regions with thousands of Points of Presence (PoP).
ElastiCache
Managed AWS service that allows you to store objects in memory rather than disk. When retrieving objects, need to check the cache first then S3.
Elemental MediaStore
Supports transfer of video files.
S3 Transfer Acceleration
Can achieve single-digit millisecond using CloudFront edge locations to accelerate data transfer over long distances. Useful for transferring data over AWS Regions.
4: Cloud Computing
first computer
- first large-scale electronic general-purpose computer the Electronic Numerical Integrator and Computer (ENIAC)
- built between 1943 and 1945
- design proposed by physicist John Mauchly
paradigm shift
- introduced 1962 by Thomas Kuhn in The Structure of Scientific Revolutions
- scientists accept predominant paradigm, but constantly challenge questioning it
- eventually new paradigm replaces the old paradigm
- e.g. heliocentric replaced geocentric view of solar system
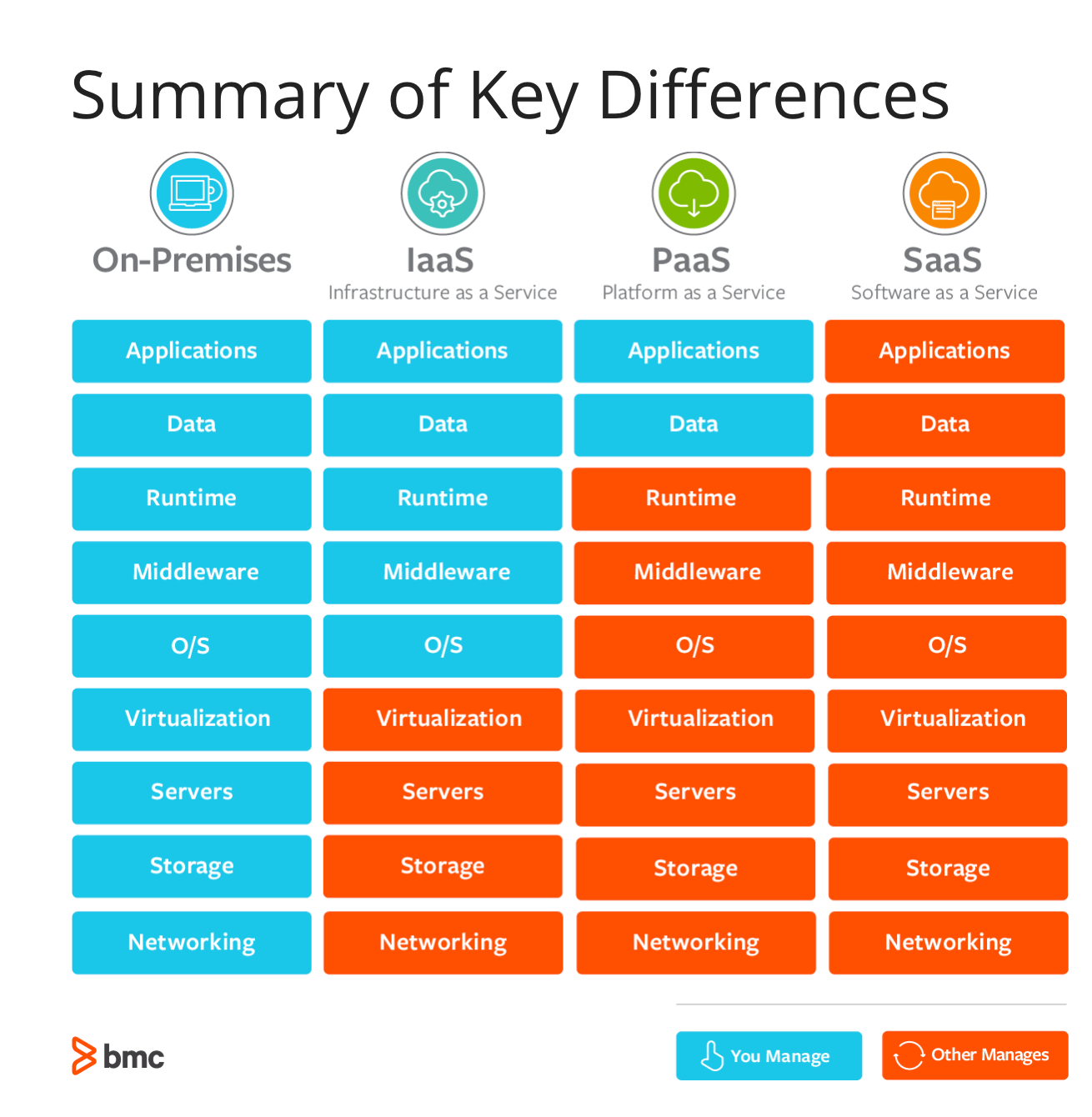
infrastructure as a service
-
advantages:
- most flexibility
- provisioning of computer, storage, and network resources can be done quickly
- resources can be used for minutes, hours, or days
- highly scalable and fault-tolerant
- more thorough control of the infrastructure
-
disadvantages:
- security must be managed at all levels, and this is costly and difficult
- legacy systems might not be able to be migrated to the cloud
- training costs might be high to onboard new staff to the system
-
examples:
- Elastic Cloud Compute (EC2)
- Elastic Block Storage (EBS)
-
use cases:
- backups and snapshots
- disaster recovery
- web hosting
- software dev environments
- data analytics
platform as a service
-
advantages:
- cost-effective and can use CI/CD principles
- high availability
- scalability
- straightforward customization and config of app
- reduction in dev effort and maintenance
- security policies simplification and automation
-
disadvantages:
- difficult to integrate on-prem and AWS systems
- regulations around data security might require securing data (not on third-party environment)
- vendor lock-in (increasing scale from IaaS to PaaS to SaaS)
- might be runtime issues because of lack of support for certain application needs
- legacy systems might be difficult to integrate with AWS
- can’t customize some layers if needed
-
examples:
- Elastic Beanstalk
- RDS
- Lambda
- Elastic Kubernetes Service (EKS)
-
use cases:
- business process management, like time clocks or company portal
- business analytics/BI for internal data analytics
- internet of things
- communications applications
- databases
- API dev
master data management
- used to define and manage company’s critical data, to provide single source of truth
- manages data throughout its lifecycle
- clean up data inconsistencies, duplicates, deliver to consumers
software as a service
-
advantages:
- reduce time, money, and effort on repetitive tasks
- shift responsibility for installing, patching, configuring, and upgrading software
- allow focus on tasks that require personal attention, such as customer service
-
disadvantages:
- interoperability with other services might not be straightforward
- vendor lock-in
- customization is very narrow
- limited features
-
examples:
- WorkMail
- WorkSpaces
- QuickSight
- Chime
ec2 - general purpose
- provides balance of compute, memory, and network resources
- can be used for variety of diverse worfklows
- ideal for apps that use compute, memory, and network resources in equal proportion, such as web servers and code repositories
- T (burstable), A (ARM chip), M (x86 dev)
ec2 - compute optimized
- ideal for compute bound applications that benefit from high performance processors
- good for batch processing, media transcoding, high performance web servers, high performance computing (HPC), scientific modeling, dedicated gaming servers
- C
ec2 - accelerated computing
- uses hardware accelerators or co-processors to perform functions
- floating point calculations, graphics processing, or data pattern matching
- F (Field Programmable Gate Array - FPGA), G (GPU), P (>$ GPU)
ec2 - memory optimized
- fast performance for workloads that process large data sets in memory
- R (memory-intensive), X (high ratio of memory to compute)
ec2 - storage optimized
- high sequential read/write access on data sets in local storage
- deliver tens of thousands of low-latency, random IOPS
- H (16 TB HDD), D (48 TB HDD), I (16 GB SSD)
amazon machine images (ami)
- different types of amazon images to build EC2 instances off of
- includes most Linux distros, Windows Server, 32/64 bit
ec2 best practices - security
- important to take advantage of identity federation, policies, and IAM
- principle of least privilege
ec2 best practices - storage
- when you shut down EC2 instance, you lose any instance storage
- use EBS mounted storage if you need to persist beyond an instance
ec2 best practices - resource management
- use instance metadata and tags to ensure resources can be tracked
ec2 best practices - resource limit
- default limits:
- limit of 20 instances per region
- 5 elastic IPs per region (including unassigned addresses)
ec2 best practices - backup, snapshots, and recovery
- important to have periodic backup schedule for EBS volumes
- deploy across multiple AZs for availability and durability
- make sure architecture can handle failovers
5: Selecting the Right Database Service
history of databases
- first database created by Edgar Codd in 1970
- SQL created by IBM researchers Raymond Boyce and Donald Chamberlin in 1970s
types of databases
- relational
- document
- key-value
- graph
- wide column storage
online transaction processing databases
- useful for workloads that have high writes and low reads
- multiple transactions per second
- data heavily normalized
third normal form (3NF)
- method of normalizing data past 1st and 2nd normal form, where every column in a table is dependent on the primary key
online analytics processing databases
- useful for read heavy workflows like large analytics queries
- doesn’t process many transactions
- data often not normalized, in star or snowflake schema (fact table and dimension tables)
ACID model
- model for transactions
- (a)tomicity - transactions either commit or they don’t; there is no partial state
- (c)onsistency - no transaction violates database invariants (a type of constraint like no account has negative balance)
- (i)solation - varying models of isolation, but this is generally more like consistency in that one transaction can’t affect another
- (d)urability - after a commit, changes are permanent (committed to disk)
BASE model
- “opposite” of ACID, although meant as a joke – more applicable to distributed systems or systems where performance hit of adhering to ACID principles is too high
- (b)asically (a)vailable - data available the majority of the time
- (s)oft state - database doesn’t have to be write consistent and replicas don’t need to be mutually consistent
- (e)ventually consistent - data stored is eventually consistent, either via replication or only on retrieval
relational databases
- data stored in rows and columns all within tables, and tables are related via foreign keys
- Relational Database Service (RDS) is primary AWS service:
- open access - Postgres, MySQL, MariaDB
- Aurora - AWS’s wrapper for Postgres and MySQL, which gives performance increases and replication out of the box
- commercial - Oracle, SQL Server
document databases
- records stored as XML, JSON, or BSON
- good for content management systems, analytics, blogging apps, or e-commerce applications
- Apache CouchDB, Amazon DocumentDB, MongoDB, Elasticsearch
- DynamoDB is fully managed NoSQL database which can achieve single-digit millisecond performance
- if faster performance (like microsecond latency) is needed, can use DynamoDB Accelerator (DAX)
key-value databases
- simply a key and a value stored as a BLOB (binary large objects)
- memcached and redis
wide-column store databases
- column family databases
- NoSQL database that can store petabyte-scale amounts of data
- Amazon Managed Apache Cassandra Service (MCS) or Amazon Keyspaces (a different variant of Cassandra)
elasticsearch
- search engine built off Lucene library
- full-text search with HTTP web interface and schema-free JSON documents
- AWS has fully managed AWS Elasticsearch offering
kendra
- enterprise search service fully managed by Amazon that uses machine learning to power it
- the content can be unstructured (HTML, MS Word, PDF), semi-structured (Excel, DynamoDB), or structured (Redshift, RDS)
in memory databases
- with increase of available RAM, in memory databases are becoming a viable solution
- additionally, SSDs blur line between volatile and nonvolatile memory in terms of speed
- ElastiCache is Amazon’s offering of memecached and redis
graph databases
- stores relationships between objects as edges and nodes
- Amazon Neptune offers full support for property graphs and Resource Description Framework (RDF), as well as the languages Gremlin and SPARQL
time-series databases
- database specifically optimized to store time series data
- Amazon Timestream is offering
- RDBMSs can store this data but they are not optimized to
ledger databases
- delivers cryptographically verifiable, immutable, and transparent transaction logs orchestrated by a central authority
- Amazon Quantum Ledger
data warehouses
- Redshift is Amazon’s data warehouse offering
- useful for BI
6: Amazon Athena
what is amazon athena
- a service that treats any file like a database table and allows you to run select statements on it
- this allows you to skip the ETL and perform queries in situ on data, speeding up processing speeds and lowering costs
- All you need to do is:
- identify the object you want to query in Amazon S3
- define the schema for the object
- query the object with standard SQL
athena supported formats - JSON & CSV
- supports comma-separated value and javascript object notation formats, as well as other delimiters
- these files are not compressed and so aren’t optimized to be used with Athena
athena supported formats - ORC
- Optimized Row Columnar, originally designed under Apache Hive and Hadoop
- provides better performance than uncompressed formats for reading, writing, and processing data
athena supported formats - Avro
- designed under Hadoop project
- uses JSON to store, but allows backward and forward compatibility by allowing the schema to be declared in file
athena supported formats - Parquet
- stores files in a flat columnar storage format, which is different than row-based approach
- columnar storage is more performant than row-based
- well-suited for compression and varying data types
presto
- athena uses presto under the hood, which is a general purpose SQL query engine
- it leverages Apache Hive to create, drop, and alter tables and partitions
- you write Hive-compliant Data Definition Language (DDL)s and ANSI SQL
- first developed as an internal project at Facebook on top of large Hadoop/HDFS clusters
- can also use massively parallel processing (MPP) via a coordinator node and multiple worker nodes
- presto can be deployed on any Hadoop implementation, and it is bundled with Amazon EMR
athena federated query
- in order to handle the many different database types, you might need a federated query (so beyond just S3)
- Amazon Athena Federated Query allows you to execute a single SQL query across data stores, simplifying code and getting results faster
- you can use many connectors supplied by Dremio, or write your own as Lambda functions
athena workgroups
- allows administrators to give different access to different groups of users
- enables separation of audiences, such as users running ad-hoc queries and users running pre-canned reports
optimizing athena - data partitions
- you can break up data into smaller groups called partitions
- care needs to be taken to choose the way that partitions are broken up so load is evenly distributed
optimizing athena - data buckets
- you can use buckets within a single partition to group single or multiple columns
- columns used to filter data are good candidates for bucketing
- if a column has high cardinality (amount of unique values) it is a good candidate
optimizing athena - file compression
- optimal file sizes for compression are 200 MB - 1 GB
- can achieve compression easily by using Parquet or ORC, which are Gzip or Bzip2 compressed
optimizing athena - file size
- want files to be a good size, so not too big and not too small
- file formats that allow splitting are ideal
optimizing athena - columnar data store generation
- if you have columnar storage, you can fine-tune the block size
- having a larger block/stripe size allows more rows per block
optimizing athena - column selection
- make sure your queries are only returning the columns needed in a query (don’t use
select * from blah)
optimizing athena - predicate pushdown
- pushing the predicate filter down to where the data lives, which allows filtering out data earlier in the process
- ORC and Parquet support this
optimizing athena - join, order by, and group by
- limit joins unless needed, and make sure left table is larger than right
- order group by cardinality, so lower cardinality first
- order by needs to be handled by single worker (that’s the only way to sort) so use
LIMITif possible
7: AWS Glue
aws glue
- fully managed ETL service
- can process tera- and petabyte scale data
- uses Apache Spark in a serverless environment under the hood
- useful for:
- population of data lakes, warehouses and lake houses
- event-driven ETL pipelines
- creation and cleansing of datasets for machine learning
AWS Glue Console
- used to create, configure, orchestrate, and develop ingestion workflows
- used to manage all other Glue objects centrally, such as connections, jobs, crawlers, as well as scheduling and job triggers
AWS Glue Data Catalog
- persistent centralized metadata repository
- operates similarly to Apache Hive metastore
- many other consumers can read it, such as EMR, Athena, or Spectrum
- only one per AWS region
- allows schema version history, data audit, and governance by tracking changes
- changed using Data Definition Language (DDL) statements or via AWS Management Console
AWS Glue Crawlers
- used to scan files, extract metadata, and populate the AWS Glue Data Catalog
- once scanned, files can be treated like SQL tables
- AWS provides crawlers for different source types, including S3, DynamoDB, many RDBMS
- any restrictions placed on underlying S3 files will persist to data in the catalog
AWS Glue Classifiers
- classifiers recognize the format of data and persist this information
- provides a certainty score from 0 to 1
- recognizes Avro, ORC, Parquet, JSON, XML, CSV, and others
AWS Glue Code Generators
- AWS Glue automatically generates python or scala ETL code
- can be edited in Glue Studio, or directly
- infrastructure as code
AWS Glue Streaming ETL
- streaming jobs can be created in Glue to process events in real-time
AWS Glue Best Practices - choosing the right worker
- workers are known as Data Processing Units (DPU)
- choose Standard, G.1X, G.2X depending on workload type (e.g. memory intensive can use G.xX)
AWS Glue Best Practices - optimized file splitting
- files can be split in blocks and processed separately and simultaneously to other files
- split files can be accessed via S3, deserialized into an AWS Glue DynamicFrame partition, and handled by an Apache Spark task
- normally a deserialized partition is not brought into memory so there is no memory pressure, but if partition is brought into memory via cache or spills onto disk an out-of-memory exception can occur
AWS Glue Best Practices- yarn’s memory overhead allocation
- Apache Yarn is resource manager used by Glue (Yet Another Resource Negotiator)
- handles memory allocation and application workloads
- allocates 10% of the total executor memory for JVM
AWS Glue Best Practices - Apache Spark UI
- using Spark UI to inspect, monitory, and optimize Glue jobs
- can view the jobs as Directed Acyclic Graphs (DAG)
AWS Glue Best Practices - processing many small files
- Apache Spark 2.2 can handle 600,000 files on standard worker
- to overcome this, you can process in batches
8: Best Practices for Security, Identity, and Compliance
Shared Responsibility Model
- responsibility for keeping apps secure on both AWS and its users
- AWS responsible for some aspects, like hardware, infrastructure, compute, users for other aspects like customer data, platform and application management, OS config, etc.
- exact distribution varies depending on service (e.g. fully managed services vs. custom on EC2)
Identity Access Management (IAM)
- secures every single service in AWS
- made up of users, which can be aggregated into groups
IAM - Users
- individuals who need access to AWS data and resources
IAM - Groups
- collection of users
- can be grouped based on job function, department, persona, etc.
IAM - Roles
- object definition to configure a set of permissions
- can be assigned to user or group or service or resource (e.g. an EC2 instance)
- best practice to use roles whenever possible instead of granting permissions directly to user or group
IAM - Policies
- a JSON or YAML document with a set of rules for what actions can be performed
- these policies can be assigned to users, groups, or roles
- policies can be:
- managed - created as standalone policies to be attached to multiple entities
- inline - created within the definition of an IAM entity and can only be assigned to that entity (they don’t have an Amazon Resource Name (ARN))
IAM - Permissions
- lists of actions that can be taken on an AWS resource (think of it as applied policies)
- identity-based policies - attached to users, groups, or roles
- resource-based policies - attached to AWS resources, e.g., S3 buckets, EC2 instances, etc.
AWS Organizations
- used to manage multiple AWS accounts in centralized location
- made up of organization, root account, organizational unit, AWS account, and service control policy (SCP)
AWS Control Tower
- enables setting up company-wide policies and apply them across AWS accounts
- without it, each policy would be applied individually to each account
AWS Guard Duty
- used to detect threats, malicious behavior, and activity from unauthorized actors
- leverages machine learning to detect threats
- it is NOT an Intrusion Prevention System (IPS), it is just an Intrusion Detection System
AWS Shield
- managed DDoS protection service
- Standard provided at no cost, Advanced costs money but provides additional protection
- can be used on EC2, ELB, CloudFront, Global Accelerator, Route 53
AWS Web Application Firewall
- firewall for web applications
- control traffic by creating rules
AWS Firewall Manager
- allows users to set up firewall rules in central dashboard, so new applications adhere to global rules
Amazon Cloud Directory
- fully managed service that creates directories (for things like org charts, device registries, etc.)
- allows multiple hierarchies instead of the typical 1 allowed by Active Directory Lightweight Directory Services (AD LDS) and Lightweight Directory Application Protocol (LDAP)
Amazon Inspector
- checks application compliance against predefined policies, generating a comprehensive report of flaws and issues sorted by severity level
Amazon Macie
- uses AI and ML to find and protect sensitive data in AWS environments
- helps with General Data Privacy Regulation (GDPR) and Health Insurance Portability and Accountability Act (HIPAA) compliance
AWS Artifact Reports
- simple service to store, manage, and access various compliance reports, e.g., SOC, PCI, NDAs
AWS Certificate Manager
- service to create, maintain, deploy public and private Secure Sockets Layer/Transport Layer Security (SSL/TLS) certs
AWS CloudHSM
- hardware security module (HSM) that allows users to generate their own encryption keys for encrypting data at rest
AWS Directory Service
- fully managed implementation of Microsoft’s AD, using the actual Microsoft AD
AWS Key Management Service (KMS)
- provides ability to create and manage cryptographic keys to encrypt data at rest
- FIPS 140-2 compliant
AWS Secrets Manager
- used to protect secrets, allowing for rotation, management, and retrieval of all sorts of secrets
AWS Single Sign-On
- used to manage users access and permissions for multiple AWS accounts
AWS Security Hub
- centralized location to see security alerts and security posture
9: Severless and Container Patterns
Advantages of Containers
- containers are more efficient, allowing a loosely coupled architecture where services do not need to know about the implementation of other services, so you can update one without needing to update another
- stateless, so no state is stored within boundaries
- leads to less infrastructure waste
- simple, as they are isolated, autonomous, and independent platforms without needing OS
- increase productivity – easier to onboard new developers
Disadvantages of Containers
- slightly slower compared to bare-metal servers
- there are ecosystem incompatibilities, for example, Docker is not fully compatible with Kubernetes (needs
dockershim) or RedHat’s OpenShift - no graphical interface
Virtual Machines
- two types of virtual machines
- system virtual machines (SVMs) - physical machine substitute, leverage hypervisor architecture
- hypervisor - can run virtual machines, aka virtual machine monitors
Docker
- very prominent container software
- freemium model – released to public in 2013 at PyCon
Dockerfile
- text file containing instructions to show how Docker image is built
- specify things like ports, OS, env vars, mounts, etc
Docker images
- container built from a Dockerfile
- portable across environments and instance types
Docker run
- utility where commands can be issued to launch containers (image instances)
- containers can be stopped, started, restarted
Docker Hub
- collection of previously created containers where Docker users share containers
- can either be a public or private Docker registry
Docker Engine
- core of Docker, which instantiates and runs containers
Docker Compose
- tool which can configure and instantiate multi-container Docker applications using a YAML file
Docker Swarm
- groups virtual or physical machines running Docker Engine into a cluster
- process of managing nodes is called orchestration
- same use case as Kubernetes
Kubernetes
- open source container orchestration platform used to automate the manual work to deploy, manage, and monitor containerized apps
- Google open sourced Kubernetes in 2015, donating to Cloud Native Computing Foundation (CNCF)
- uses many applications and extensions to enhance orchestration
- Registration services: Atomic Registry, Docker Registry
- Security: LDAP, SELinux, RBAC, OAUTH
- Networking services: OpenvSwitch and intelligent edge routing
- Telemetry: Kibana, Hawkular, and Elastic
- Automation: Ansible playbooks
Kubernetes Advantages
- faster development and deployment
- cost efficiency
- cloud-agnostic deployments
- management by cloud provider
Amazon Elastic Container Service for Kubernetes (EKS)
- managed wrapper around Kubernetes kernel
- greatly simplifies restarting and setting up containers, persisting data, etc.
Amazon Elastic Container Service (ECS)
- quick solution to host containers at scale, so ideal for simpler workloads
AWS Fargate
- serverless compute engine for container management which can be used with EKS or ECS
- containers as a service, meaning that the provisioning and management of container infrastructure is managed by AWS
AWS Batch
- great for long-running compute jobs that do not need low latency turn times
- cheaper than other options, but slower
- job: unit of work
- job definitions: description of jobs to be executed (what parameters, cpu, ram, etc.)
- job queues: list of work to be completed by jobs
- compute environment: compute resources to run job
10: Microservice and Event-Driven Architectures
microservice
- a software application that is structured as loosely coupled, easily deployable, and testable, and is organized in a well-defined business domain
layered architecture
- code is implemented in layers as a “separation of concerns”
- generally, top most layer communicates with users and other systems, middle layer handles business logic, and bottom layer is data persistence
- allows applications where only the top layer is publicly accessible
- we can swap out layers for other tech if the layers are loosely coupled
event-driven architecture
- creating, messaging, processing, and storing events are the critical functions of a system
- an event is any change in the state of the system
- not all changes are events – only meaningful changes are events
event producer
- detects change in state, then generates the event and notifies others of the change by writing to a queue
event consumer
- fetch events from queue (in async way), then performs action based on event
event streaming
- events are popped off queue as soon as one consumer processes the event
- useful for workloads that need to be highly scalable and can be highly variable, since scaling is just adding more consumers
- use case is for events that need to be processed exactly once but order doesn’t matter
pub-sub model
- allows several consumers to process the same message
- potentially guarantees order of messages received
- useful for use cases where more than one consumer needs to receive messages
benefits of event-driven architecture
- no need to poll which is expensive, since push mechanism alerts consumers when new event occurs
- dynamic targeting means there is no need to keep track of data consumers
- keeps communication between producers and consumers simple
- allows for decoupling and scalability, as each producer and consumer can adapt to their workload in isolation
disadvantages of event-driven architecture
- can’t solve all problems, and the added complexity of setting up a message queue might not be worth it
- popular with IoT workflows, but not others
- difficult to troubleshoot problems because system is asynchronous
plugin/microkernel architecture
- consists of a core system with features added via ‘plugins’ or extensions